小甲鱼视频 小甲鱼作业及答案 Python黑魔法手册 python基础
Python 3 教程 Python 教程 廖雪峰-Python 程序员修炼手册 Python后端开发 Python Tutor
重要的键盘鼠标操作
- 注先前的Fn键,笔记本锁定了,可以用Fn+ESC恢复原有的功能。
- pycharm下,运行:Shift + F10
- 自动补全前面曾经出现过的单词: Alt+/
- 调出帮助文档:选中然后shift F1
- 一句内容过长,使用行连接符\
- pycharm 代码,选定任何一行,代码栏下面(灰色的一小栏)会显示控制流结构,很重要
基础要点:
- 缩进决定逻辑层次
- 避免 tab 与空格混合的缩进风格,虽然我们知道大多数编辑器默认 tab 制表符就是 4 个空格
- print(dir(obj))得到obj对象的所有属性和方法
pycharm安装和设置
我的miniconda安装在D\miniconda,我在Anaconda Prompt输入 conda create --name my_env python=3.6 ,这将会创建一个新的虚拟环境,并在其中安装Python 3.6,该文件夹就在D:\miniconda\envs\my_env。激活新创建的环境,在Anaconda Prompt输入 conda activate my_env 。
C:\Users\hujie\AppData\Local\JetBrains\PyCharm2023.3\demo\PyCharmLearningProject\venv
变量
数值和布尔
运算和进制转换
- 增强型赋值运算:我们常用 a += 2表示a = a+2,这里的+也是是其他运算符。
- / —— 浮点除法
- // —— 整数除法
- % —— 取余数
- ** —— 幂运算——pow(a, b)
- divmod(a, b)——元组(c, d)分别对应商和余数;
- 进制转化:
- int("0xff",16)得到的就是十进制下的255,其中16表示0xff是16进制
- 如果要将16进制的0xff转换为2进制,那么还是得用十进制作为过渡,bin(int("0xff",16)),得到0b11111111
range的使用
- range(start, end, [step]) —迭代器,用来产生指定范围的数字序列
- for i in range(10) 产生序列:0 1 2 3 4 5 6 7 8 9 — 默认从0开始
- for i in range(3,10) 产生序列:3 4 5 6 7 8 9
- for i in range(3,10,2) 产生序列:3 5 7 9
布尔
- is —— 同一运算符:是不是同一个对象,即id(object)是否相等;
- == —— 相等运算符:值是不是相等
- is 运算符比 == 效率高,在变量和 None 进行比较时,应该使用 is。
- 逻辑运算符:
- or —— if a or b
- and —— if a and b
- not —— if not
- bool —— bool(a)将a转成bool类型
- 在 if、while 等条件判断语句里,判断条件会自动进行一次bool的转换
- bool and a or b —— 类似labview中的select function
- 当bool条件为真时,结果是a;
- 当bool条件为假时,结果是b;
- and-or似乎只是替代if-else而已,其实不然,在特殊场合,不能用if语句,这时就只能选择and-or技巧了,比如lambda函数中(后面会详述);
- in /not in —— 成员资格操作符, 判断某个字符(子字符串)是否存在于某个list或者字符串中;
# coding: gbk
bool(0)
bool(0.0)
bool()
bool(())
bool([])
bool({})
bool(None)
# 以上都为False
a = False
bool(a==False) # 为真
a = '123'
if a: # 判断为真
print ('this is not a blank string') #输出这句话
value = 2 < 5
print(value) # 输出True
a = 10
b = 20
c = 30
result = a and b or c
print(result) # a为真,所以输出b,即20
print ((a > 0) and 'big' or 'small')
# 如果a >0成立就输入big,否则输出small
a = ["a","b","c"]
print("a" in a) # 输出True
字符串-基本操作
(和list的用法类似,有些用法就不在list里面赘述)
# coding: gbk
# 遍历
word = "helloworld"
for c in word:
print(c)
# 索引
print(word[0]) # 输出h,索引从0开始
print(word[-2]) # 输出导数第二个字符
# 切片—— [起始偏移量 start:终止偏移量 end:步长 step]
print(word[5:7])
print(word[:]) # 切片,输出helloworld
print(word[::-1]) # 反向切片,输出dlrowolleh
# 连接
a = ','.join('word')
print(a) # 输出w,o,r,d
# 分割
sentence = 'I am an English sentence'
a = sentence.split() # 默认按照空格/换行/制表符分割
section = 'Hi. I am the one. Bye.' # 指定分隔符
a = section.split('.') # 得到['Hi', ' I am the one', ' Bye', '']
# 替换
a = 'abcdefc'
a = a.replace("c","高") # 新的变量,新的物理地址
print(a) # 输出:ab高def高
# 大小写转换
s = "What Is Your Name?"
print(s.swapcase()) # 大小写互换
print(s.lower()) # 小写
print(s.upper()) # 大写
print(s.capitalize()) # 首字母大写
print(s.title()) # 每个单词首字母大写
# 去除首尾特定字符串
greeting = "#Hello World#"
stripped_greeting = greeting.strip("#")
print(stripped_greeting) # 输出:Hello World
greeting.lstrip() # 去除左边的
greeting.rstrip() # 去除右边的
print(" abc ".strip) # <built-in method strip of str object at 0x000001C1BFE5BA70>
print(" abc ".strip()) # abc
# 注意remove函数是用于列表的,不能直接用于字符串
字符 → list:字符串的修改替换,可以先将一个字符串变成list,然后进行操作,因为list比较灵活,修改(增加元素、删除元素、替换元素)或者切片比较方便。而字符串本身要修改的话,不能修改自身,只能重新建立一个内从地址,存储修改后的字符串。
用数学符号拼接+和复制*n
- "3"+"2" ==> "32"
- 元组和列表也可以,比如[10,20,30]+[5,10,100] ==>[10,20,30,5,10,100]
- "txt"*3 ==> "txttxttxt"
- 元组和列表也可以,比如[10,20,30]*3 ==> [10,20,30,10,20,30,10,20,30]
字符串拼接,不推荐使用+,推荐使用join函数,效率更高;每+用一次,得到一个新的对象,浪费内存。比如循环执行a+="my name",那么每循环一次,生成一个新的变量。但是如果用list就比较好,因为list大小可变,每循环一次,在list末尾加上一个"my name",最后将list中的内容都join一下。
【可变字符串】:一般来说,字符串创建之后是不可变的,但是如果真的要频繁修改某个字符串(在原地址上修改),那么可以使用 io.StringIO对象或 array 模块 。具体看高老师的资料,这里不赘述。(感觉用到的概率不大)
文本分析:对于一个长文本(字符串)a,可以进行如下的文本分析的操作
- len(a) 字符串的长度
- a.startswith("xxxxx") 以指定字符串开头,给出布尔值
- a.endswith("xxx")以指定字符串结尾,给出布尔值
- a.find("xx") 第一次出现特定字符串的位置 #如果找不到,返回-1
- a.index("xx") 第一次出现特定字符串的位置 #如果找不到,抛出异常
- a.rfind("xx") 最后一次出现特定字符串的位置
- a.count("xx") 指定字符串出现的次数
- a.isalnum() 所有字符全是数字或字母,给出布尔值
字符的编码
- python3直接支持Unicode(16位,二进制),可以表示世界上任何书面语言的字符( LabVIEW 没有完全支持 unicode),Python3的字符默认就是16位Unicode编码,ASCII码(8位,只够英文)是Unicode编码的子集;
- ord() —— 把字符转换成对应的Unicode码,比如ord("A")得到65,ord("高")得到39640;
- chr() —— 把十进制数字转换成对应的字符,比如chr(66)得到'B';
- ord是"ordinal"(序数)的缩写,即编号,chr是 "character"即字符的缩写,ord()函数和chr()函数互相对应;
字符串驻留:字符串驻留(String Interning)是Python优化内存使用和提升字符串操作性能的一种机制。该机制的主要思想是,对于内容相同且不可变的字符串,只在内存中保存一份副本,这样相同内容的字符串就可以共享内存空间。
注:我在pycharm python3.11中只要a和b对应的字符串内容相同,就会启用字符串驻留机制,这与一些资料的讲法不一致(包含特定字符才会启用)。
字符串比较和同一性比较:
(1) ==, !=对字符串进行比较,是否含有相同的字符。
(2) is / not is,判断两个对象是否同一个对象。比较的是对象的地址,即 id(obj1)是否和 id(obj2)相等。 即变量引用的地址是不是一样的。
字符串-正则表达式
此部分需要修改,让内容更简洁
【正则表达式】(Regular expression):正则表达式的作用就是定下一定的规则,然后按照这个规则去寻找符合条件的字符串。正则表达式就是记录文本规则的代码。
(1) 最简单的正则表达式,只有基本的字母或数字,它满足的匹配规则就是完全匹配
import re
text = "Hi, I am Shirley Hilton. I am his wife."
m = re.findall( r"hi", text)
if m:
print (m)
else:
print ('not match')
# output is ['hi', 'hi']如果用“\bhi\b”匹配不到任何结果。但“\bhi”的话就可以匹配到1个“hi”,出自“his”。“[Hh]i”的意思是既匹配“Hi”,又匹配“hi”。
\b表示字母数字与非字母数字的边界, 非字母数字与字母数字的边界。
比如"site sea sue sweet see case sse ssee loses"中site 以前一后两个\b 所以如果用‘\b \b’索引,会找出任意单词前后部分的边界。\w匹配字母或数字或下划线或汉字等。“隐式位置” \b,匹配这样的位置:它的前一个“显式位置”字符和后一个“显式位置”字符不全是 \w。
\w和 \W
“*”表示任意数量连续字符
r"\bhi"表示不对""内的字符串进行转义。\有转义的功能,比如\n表示换行。r是raw的意思,表示按照原始的模样。
import re的re就是python的正则表达式模块(库),findall是其中一个方法,用来按照提供的正则表达式,去匹配文本中的所有符合条件的字符串。返回结果是一个包含所有匹配的list。
“\S”,它表示的是不是空白符的任意字符(一个)。匹配结果为['H', 'i', ',', 'I', 'a', 'm', 'S', 'h', 'i', 'r', 'l', 'e', 'y', 'H', 'i', 'l', 't', 'o', 'n', '.', 'I', 'a', 'm', 'h', 'i', 's', 'w', 'i', 'f', 'e', '.']。
“.”在正则表达式中表示除换行符以外的任意字符(一个)。“i.”去匹配,就会得到 ['i,', 'ir', 'il', 'is', 'if']。
懒惰匹配:“I.*?e” 结果为['I am Shirle', 'I am his wife'] (先匹配头,碰到符合条件的尾巴就整体匹配一下,继续寻找下一个头)
贪婪匹配:“I.*e” 结果为 ['I am Shirley Hilton. I am his wife'] (先匹第一个头,然后匹配最后一个尾巴)
例子:最后留一道习题: 从下面一段文本中,匹配出所有s开头,e结尾的单词。 site sea sue sweet see case sse ssee loses
解答为:r'\bs\S*e\b'
运行结果为['site', 'sue', 'see', 'sse', 'ssee']
说明:前后\b把单词隔开,中间s表示开头,e表示结尾,*表示任意字符(sXXXe),而\S表示没有空格(排除sXX XXe)。
参考资料:
(1) 正则表达式 \b
(2) python爬虫之正则表达式
(3) 正则表达式30分钟入门教程
列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
列表list的简单的用法
# coding: gbk
import random
a = "happy"
b = list(a) # str类 → list
print(b) # 输出:['h', 'a', 'p', 'p', 'y']
m = list(range(1, 10)) # type类 → list
print(m) # 输出: [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(type(range(1, 10))) # 输出:<class 'range'>
i = [365, 'everyday', 0.618, True] # 元素不同类型
print(i[-3]) # 输出:everyday
print(i[2:4]) # 输出:[0.618, True]
print(i[:3]) # 输出:[365, 'everyday', 0.618]
i.append(1024) # 原list变为 [123, 'everyday', 0.618, True, 1024]
i.extend(["a", "c"]) # [365, 'everyday', 0.618, True, 1024, 'a', 'c']
# append是增加单个元素,extend是增加多个多个元素组成的list
del i[0] # ['everyday', 0.618, True, 1024, 'a', 'c']
i.remove('everyday') # [0.618, True, 1024, 'a', 'c']
print(i.pop(0)) # 删除列表a中的第一个元素,并将这个元素作为返回值。pop就是弹出的意思
i[0] = 123 # 将列表的第一个元素变为123。
i.clear() # 清空列表中的元素,得到一个空列表
i = [365, 'everyday', 0.618, True]
for n in i: # 遍历
print(n)
# 逆序排——三种方式的区别
i.reverse() # reverse()方法,没有返回值,原地址修改列表
print(i) # 输出:[True, 0.618, 'every day', 365]
print(reversed(i)) # <list_reverse iterator object at 0x000001AAFE093FD0>
# reversed()函数返回一个反向迭代器,需要使用list将其转化为列表
print(i[::-1]) # 切片的方式实现list元素反向排序
# 复制——两种的区别
a = i # a和i具有相同的物理地址,栈中的两个元素a和i都对应堆中的同一个对象
a = [] + i # a和i的对象数值和类型相同,但是物理地址不同
# 排序——两种方法的区别
a = [20, 10, 30, 40]
a.sort() # sort()方法,原地修改,没有返回值,默认升序排列
a.sort(reverse=True) # 降序排列
random.shuffle(a) # 打乱顺序,同样没有返回值
a = sorted(a) # 新建列表,有返回值
c = sorted(a, reverse=True) # 新建列表,降序多维列表:列表中的元素是列表,那么索引的时候,必须有多个参数确定核心元素的位置,最常见的就是二维列表。
# coding: utf-8
a = [
["高小一", 18, 30000, "北京"],
["高小二", 19, 20000, "上海"],
["高小一", 20, 10000, "深圳"], ]
for m in range(3):
for n in range(4):
print(a[m][n], end="\t")
print() # 打印完一行,换行
""""输出
高小一 18 30000 北京
高小二 19 20000 上海
高小一 20 10000 深圳
"""
在实际开发中,适当地使用列表解析(【遍历法】(traversing method)和【列表推导式】(list comprehension))可以让代码更加简洁、易读,降低出错的可能。
# coding: gbk
# 找出一个list中的偶数,然后组合成新的list
# 方法1——遍历法
list_1 = [1, 2, 3, 5, 8, 13, 22]
list_2 = []
for i in list_1:
if i % 2 == 0:
list_2.append(i)
print(list_2)
# 方法2——列表推导式
list_1 = [1, 2, 3, 5, 8, 13, 22]
list_2 = [i for i in list_1 if i % 2 == 0]
# list_1中的偶数取出来,然后将这些偶数都除以2,然后输出得到的新的list_2,那么可以写成
# list_2 = [i / 2 for i in list_1 if i % 2 == 0]
print(list_2)
# 把1到100的整数里,能被2、3、5整除的数取出,以分号(;)分隔的形式输出
# 方法1
print(';'.join([str(i) for i in range(1, 101) if i % 2 == 0 and i % 3 == 0 and i % 5 == 0]))
# 方法2 (更加容易看懂)
a = list(range(1, 101))
list_2 = [str(i) for i in a if i % 2 == 0 and i % 5 == 0 and i % 3 == 0]
print(";".join(list_2))
# 结果 30;60;90
其他有关list的知识
- insert()方法——不推荐,数组需要移动插入位置后面的所有元素,因此其操作成本较高,例子a.insert(2,100),其中2表示位置编号。
- append()方法——推荐使用,原地修改列表对象,是真正的列表尾部添加新的元素,速度最快。
- a=a+[50]——不是原地扩展;
- del函数——会出现元素的拷贝,所以效率不高,比如del i[2]

- list中相邻元素的地址:对于列表a = [10, 20, 30, 40]来说,list里面的物理地址是连续的, 每个元素对应16位的unicode;
- 列表和字符串很多函数用法是相通的;
- 列表和字符串很多函数用法是相通的不要一边遍历,一遍修改/删除,可以先挑出有用的元素;
元组
【元组】(tuple)叫作“多元组”,多个元素(数字、字符串随意)按一定顺序排列得到的组合,类似labview中的簇cluster,C语言中的结构struct。
注意:包含一个元素的元组(2,),如果写成(2)则被认为是int类型。
总的来说,如果需要存储的数据是不可变的,推荐使用元组;如果需要频繁地对数据进行增删改查,可以选择列表。元组和列表的区别体现在以下几个方面:
可变性(Mutability):
- 列表是可变的,比如添加、删除或修改元素;
- 元组是不可变的,即一旦创建就不能修改其内容;
性能:由于元组是不可变的,相对于列表,元组的访问速度更快。
存储空间:列表的存储空间略大于元组,因为列表是可变的,需要额外的空间来存储指向对应元素的指针和已分配的长度大小。
作为字典的键:列表不能作为字典的键,而元组可以作为字典的键。
语法表示:列表用 [];元组用 (),但在创建包含一个元素的元组时,需要在元素后面加上逗号,以区分它与普通括号 single_element_tuple = (4,)以避免歧义;
元组的操作:索引、切片、连接操作、成员关系、比较运算、排序 —— 返回一个list、计数(元组长度 len()、最大值 max()、最小值 min()、求和 sum()等)。
元组的创建:
# coding: gbk
a = 10, 20, 30
a = (10, 20, 30)
b = tuple("abc")
print(b) # 输出:('a', 'b', 'c')
c = tuple(range(3))
print(c) # 输出:(0, 1, 2)
d = tuple([2, 3, 4])
print(sorted(d)) # 输出:[2, 3, 4] 注意得到的是list
e = zip(a, b, c, d) # 输出:将多个列表对应位置的元素组合成为元组,并返回这个 zip 对象。
print(e) # 输出:<zip object at 0x000001F34D7A4C00>
print(list(e)) # 输出:[(10, 'a', 0, 2), (20, 'b', 1, 3), (30, 'c', 2, 4)]
f = divmod(13, 3)
print(f) # 输出:(4, 1)
# 元组没有元组推导式 (<gen expr>表示generator expression)
h = (x for x in range(1, 100) if x % 9 == 0) # 得到一个生成器对象<generator object <gen expr> at 0x0000000002BD3048>
for x in h:
print(x, end=" ") # 输出:9 18 27 36 45 54 63 72 81 90 99
for x in h:
print(x, end=" ") # 没有输出,因为一个生成器只能运行一次
字典
空间换时间,字典格式 d = {key1 : value1, key2 : value2} ,键必须是唯一的,键只能是简单对象,比如字符串、整数、浮点数、bool值。
字典的创建和基本操作
# coding: gbk
# 方法1. 创建有数据的字典 (比较常用)
r1 = dict(name="高小一", age=18, salary=30000, city="北京")
print(r1, type(r1))
# 输出结果 {'name': '高小一', 'age': 18, 'salary': 30000, 'city': '北京'} <class 'dict'>
# 方法2. 用zip函数来创建字典对象
k = ["name", "age", "job"]
v = ["gaoqi", 18, "teacher"]
d = dict(zip(k, v))
print(d)
# 输出结果 {'name': 'gaoqi', 'age': 18, 'job': 'teacher'}
# 方法3. 用fromkeys创建值为空的字典
a = dict.fromkeys(["name", "age", "job"])
print(a)
# 输出结果 {'name': None, 'age': None, 'job': None}
# 方法4. 字典推导式-{key_expression : value_expression for 表达式 in 可迭代对象}
my_text = ' i love you, i love sxt, i love gaoqi'
char_count = {c: my_text.count(c) for c in my_text}
print(char_count)
# 输出结果 {' ': 9, 'i': 4, 'l': 3, 'o': 5, 'v': 3, 'e': 3, 'y': 1, 'u': 1, ',': 2, 's': 1, 'x': 1, 't': 1, 'g': 1,
# 'a': 1, 'q': 1}
# example of using dict
score = {"萧峰": 95, "段誉": 97, "虚竹": 89}
print(score.get("段誉")) # 推荐使用,如果找不到的话,返回None
print(score["萧峰"]) # 如果找不到的话,会报错
score["虚竹"] = 91 # 重新赋值
score["慕容复"] = 88 # 增加元素
del score["段誉"] # 删除元素
字典的遍历:遍历字典的时候默认是遍历value
dict = {'Name': 'Runoob', 'Age': 7}
for i,j in dict.items(): #分别对应字典中的键和值
print(i, ":\t", j)
#输出结果
Name : Runoob
Age : 7
d = {'Name': 'gaoqi', 'Age': 18,"address":"西三旗001号楼" }
for x in d: # 遍历字典所有的key
print(x)
for x in d.keys(): # 遍历字典所有的key
print(x)
for x in d.values(): # 遍历字典所有的value
print(x)
for x in d.items(): # 遍历字典所有的"键值对"
print(x)
# 第一个结果
Name
Age
address
# 第二个结果
Name
Age
address
# 第三个结果
gaoqi
18
西三旗001号楼
# 第四个结果
('Name', 'gaoqi')
('Age', 18)
('address', '西三旗001号楼')
例子:用列表和字典存储下表信息,并打印出表中工资高于15000 的数据
# coding: gbk
r1 = dict(name="高小一", age=18, salary=30000, city="北京")
r2 = dict(name="高小二", age=19, salary=20000, city="上海")
r3 = dict(name="高小三", age=20, salary=10000, city="深圳")
tb = [r1, r2, r3]
for x in tb:
if x.get("salary") > 15000:
print(x)
print(tb[1].get("salary")) # 获得第二行的人的薪资
for i in range(len(tb)): # 打印表中所有的薪资
print(tb[i].get("salary"))
for i in range(len(tb)): # 打印表中所有的数据
print(tb[i].get("name"), tb[i].get("salary"), tb[i].get("city"))
集合
其实我们可以发现前面的元组、列表、字典还是存在一些缺陷的,比如删除特定元素,每次只能删除一个。下面介绍的集合在这方面更具有灵活性。
正如我们数学上集合的概念,集合就是里面一堆东西放在一起,并不区分每个元素的先后顺序,重要的只是某个元素是在集合里面还是在集合外面。对集合来说,你输入时候的元素在集合中的顺序,并不代表输出时候的顺序,顺序只取决于物理地址。特别注意:集合会删除重复的元素。
# coding: gbk
m = {3, 5, 7} # 创建集合
a = ['a', 'b', 'c', 'b']
b = set(a) # 将列表/元组转为集合
b.add(9) # 添加元素,没有返回值
b.remove('a') # 删除a这个元素,如果不存在a,则抛出异常
b.discard('a') # 删除a这个元素,如果不存在a,不会抛出异常
b.clear() # 清空
c = {'b', 'c', 'e'}
print(b | c) # 并集
print(b & c) # 交集
print(b.difference(c)) # b中删除和c中重复的元素
d = {x for x in range(1, 100) if x % 9 == 0} # 集合推导式
print(d) # 输出:{99, 36, 72, 9, 45, 81, 18, 54, 90, 27, 63}
变量的引用和拷贝
栈和堆
下图是两个赋值过程:a = 3,b = "我爱你"。
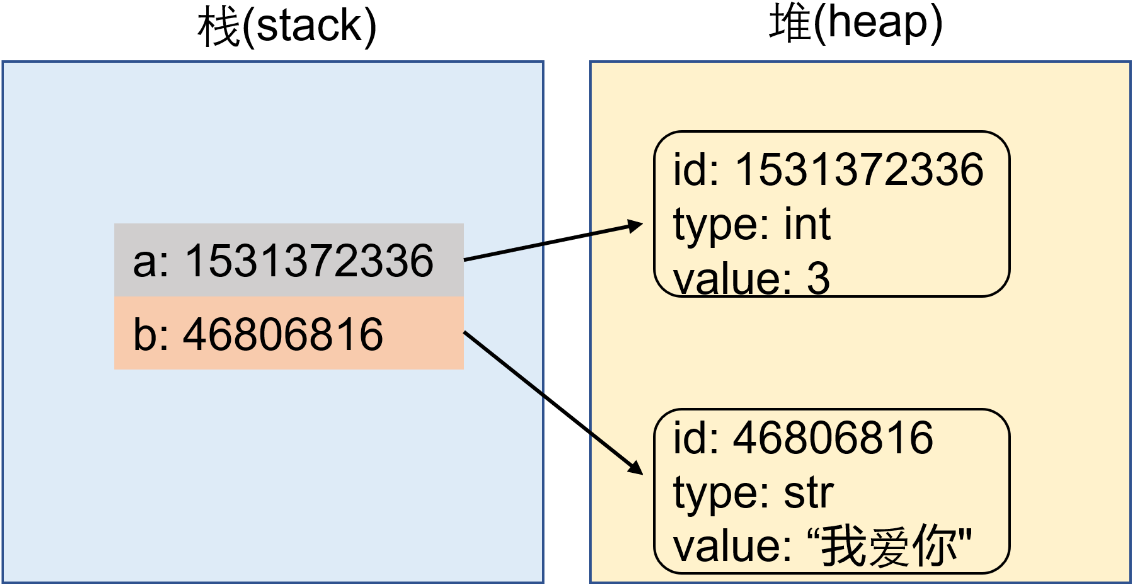
- 变量是对象的引用,因为变量存储的是对象的地址,变量通过这个地址来引用对象。
- 变量——栈内存,对象——堆内存
- 【垃圾回收机制】(garbage collection mechanism):del a 删除a其实是删除栈,而3这个对象没有变量取引用,就会被垃圾回收器回收,清空内存空间。
- a = b = 3 等价于a = 3然后b = 3,二者的物理地址一样。
- a,b,c = 4,5,6 分别赋值。 a, b = b, a表示a和b的值互换。
- float(3) 是生成一个新的对象,而不是修改原来的对象,int(), round()也是一样。
- a = 3
a = a+1也是生成一个新的对象。
栈和堆对比:
浅拷贝和深拷贝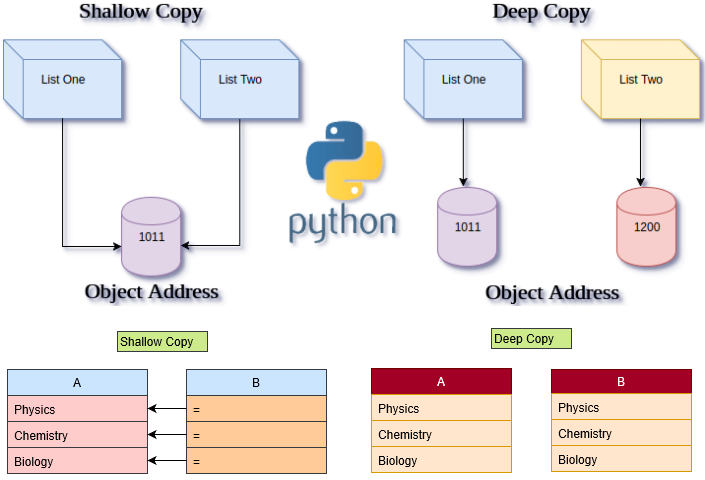
A【shallow copy】 is one which makes a new object stores the reference of another object. While, in 【deep copy】, a new object stores the copy of all references of another object making it another list separate from the original one.
Thus, when you make a change to the deep copy of a list, the old list doesn't get affected and vice-versa. But shallow copying causes changes in both the new as well as in the old list. This copy method is applicable in compound objects such as a list containing another list.
# coding: gbk
import copy
# 浅拷贝
a = [[1, 2, 3], [4, 5, 6]]
b = copy.copy(a)
print(a) # 输出:[[1, 2, 3], [4, 5, 6]]
print(b) # 输出:[[1, 2, 3], [4, 5, 6]]
a[1][2] = 23
b[0][0] = 98
print(a) # 输出:[[98, 2, 3], [4, 5, 23]]
print(b) # 输出:[[98, 2, 3], [4, 5, 23]]
# 深拷贝
c = [[7, 8, 9], [10, 11, 12]]
d = copy.deepcopy(c)
print(c) # 输出:[[7, 8, 9], [10, 11, 12]]
print(d) # 输出:[[7, 8, 9], [10, 11, 12]]
c[1][2] = 23
d[0][0] = 98
print(c) # 输出:[[7, 8, 9], [10, 11, 23]]
print(d) # 输出:[[98, 8, 9], [10, 11, 12]]
程序结构
if 语句
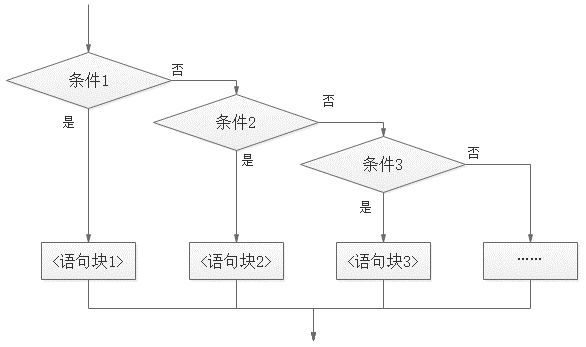
if.....elif.....elif........else 多分支选择结构,最后一个else是可选的,这其实就是C语言中的switch语句(python中没有switch),之前我们在arduino用到过,也类似labview中的条件结构。一旦满足某个条件,就跳出整个大if。注意事项:
- 赋值符不能出现在条件表达式中,比如 if 3 < c and (c = 20):
- if......if.......if....... 是顺序结构,不是多分支选择结构,需要把每一个if都执行一遍。
- 【三元条件运算符】(ternary conditional operator):条件为真时的值 if (条件表达式) else 条件为假时的值,比如
num = input("请输入一个数字")
print( num if int(num)<10 else "数字太大")
for循环-break-continue
# this shows how to jump out of a loop
for i in range(10):
a = input()
if a == "EOF":
break
# this shows how to skip one loop and do the rest loop stuff
data = [50,58,70,80,90,75]
sum =0
for score in data:
point = int(score)
if point < 60:
continue
sum += point
print(sum)- break 语句:在 while 循环或者 for.... in 循环,想提前跳出循环,可以用 if....break 语句,其中if给出跳出的限定条件,特别注意对齐方式;
- continue语句:break 是彻底地跳出循环,而continue只是略过本次循环的余下内容,直接进入下一次循环,多个循环嵌套时,continue 也是应用于最近的一层循环。(上面代码中低于60分的不计入总成绩);
- 无论是 continue 还是 break,其改变的仅仅是当前所处的最内层循环的运行,如果外层还有循环,并不会因此略过或跳出。
else 语句
while/for 循环......else 语句,为了体现出这种写法特特定场景下的简洁高效性,需要和break连用,当执行了break之后else的语句就不会执行了。
while/for......break......else......
# 例子:员工一共 4 人,录入这 4 位员工的薪资,全部录入后,
# 打印提示“您已经全部录入 4 名员工的薪资”,最后,打印输出录入的薪资和平均薪资
salarySum= 0
salarys = []
for i in range(4):
s = input("请输入一共 4 名员工的薪资(按 Q 或 q 中途结束)")
if s.upper() == 'Q':
print("录入完成,退出") # 给出中途退出的机制
break
if float(s) < 0:
continue
salarys.append(float(s))
salarySum += float(s)
else:
print("您已经全部录入 4 名员工的薪资")
print("录入薪资:",salarys)
print("平均薪资{0}".format(salarySum/4))
参考资料:
(1) Python for...else... 语句
循环代码优化
- 尽量减少循环内部不必要的计算;
- 嵌套循环中,尽量减少内层循环的计算,尽可能向外提;
- 局部变量查询较快,尽量使用局部变量。
#循环代码优化测试
import time
start = time.time()
for i in range(1000):
result = []
for m in range(10000):
result.append(i*1000+m*100)
end = time.time()
print("耗时:{0}".format((end-start)))
start2 = time.time()
for i in range(1000):
result = []
c = i*1000
for m in range(10000):
result.append(c+m*100)
end2 = time.time()
print("耗时:{0}".format((end2-start2)))
其他优化手段:
1. 连接多个字符串,使用 join()而不使用+
2. 列表进行元素插入和删除,尽量在列表尾部操作
函数
Python的函数分为四类:
- 【用户自定义函数】(user-defined functions);
- 【内置函数】(Built-in Functions):str()、int()、len()、input()、range()等,内置函数列表,可以;
- 【标准库函数】(Standard Library Functions):需要import.obj导入,执行help("modules")查看所有标准库函数,比如:
- math库,用于数学运算
- random,随机数
- time,时间处理
- file,文件处理
- datetime库,用于处理日期和时间
- os库,和操作系统交互
- sys库,和Python解释器进行交互
- 【第三方库函数】(Third-party library):
- NumPy - Numerical Python,用于科学计算的库,提供了多维数组和矩阵操作功能
- Pandas - Python Data Analysis Library,用于数据分析和处理的库,提供了数据结构和数据分析工具
- Matplotlib - 用于绘制图表和图形,数据可视化
- Requests - 用于发送HTTP请求的库,简化了与Web服务的交互
- Scipy - 用于科学和工程计算,特别是对于科学和工程中的数值积分、优化、线性代数、统计和信号处理等
- Django - 一个用于构建Web应用程序的高级Python Web框架
- Flask - 轻量级的Web应用框架,用于构建小型至中型的Web应用
- TensorFlow - 用于机器学习和深度学习的库
- PyTorch - 用于机器学习的深度学习库
- Scikit-learn - 用于机器学习的库,包含了许多常见的机器学习算法
- Beautiful Soup - 用于从HTML和XML文件中提取信息的库
函数的格式和参数
Python 中,一切都是对象。实际上,执行 def 定义函数后,系统就创建了相应的函数对象,也就是有栈和堆。函数对象后面的 () 就是调用的意思。
def tes():
print("abcdefg")
tes() #output abcdefg
c = tes
c() #output abcdefg
print(tes) # output <function test01 at 0x0000011D56D704A0>
print(c) # output <function test01 at 0x0000011D56D704A0>
print(id(tes)) # 2241944421536
print(id(c)) # 2241944421536
自定义函数格式说明:
"""
自定义函数格式说明
def function_name(paramters):
""文档字符串"" #解释说明这个函数的作用,大概说一下功能的实现方式
函数体/若干语句
"""
# example_1
def sayHello():
print ('hello world!')
sayHello() # test
# example_2
def printMax(a,b):
"""实现两个数的比较,并返回较大的值""" #解释说明这个函数的作用
if a > b:
print(a,"larger value")
else:
print(b, "larger value")
printMax(10, 20) #test
help(printMax.__doc__) #可以打印输出函数的文档字符串,即上面三个双引号里面的内容上面的 printMax 函数中,在定义时写的 printMax(a,b)。a 和b 称为【形式参数】(formal parameter=parameter),简称形参。也就是说,形式参数是在定义函数时使用的。 形式参数的命名只要符合“标识符”命名规则即可。在调用函数时,传递的参数称为【实际参数】(actual parameter=argument),简称实参。printMax(10,20)中,10和20就是实际参数。在不很严格的情况下,现在二者可以混用,一般用argument,而parameter则比较少用。
参数列表:
(1) 圆括号内是形式参数列表,有多个参数则使用逗号隔开
(2) 形式参数不需要声明类型,也不需要指定函数返回值类型
(3) 无参数,也必须保留空的圆括号
(4) 实参列表必须与形参列表一一对应
函数中参数的传递
函数的参数传递本质上就是:从形参到实参的赋值操作。python中一切皆对象,所有赋值操作都是"引用的赋值"。所以,python中参数的传递都是引用的传递(pass-by-object-reference),不是值传递。具体分为:
对【可变对象】(列表、字典、集合和自定义的对象等)进行写操作——直接作用于原对象本身。
对【不可变对象】(数字、字符串、元组、布尔值、function等)进行写操作——会产生一个新的对象空间,并用新的值填充这块空间。
注:虽然函数对象本身是不可变的,但其可调用的行为和内部状态可以通过闭包或类实例来改变。因此,函数对象通常不被严格视为不可变对象。
Example—传递可变对象

b = [10, 20]
def f2(m):
print("m:",id(m)) # b和 m是同一个对象
m.append(30) # 由于列表 m 是可变对象,直接修改这个对象,而不是创建拷贝
f2(b)
print("b:",id(b)) # 打印 b 的 id,确认与 m 的 id 相同
print(b) # 输出 [10, 20, 30]
如果你尝试直接修改形参本身,例如将形参重新赋值为一个新对象,这不会影响到原始的实参。
def modify_list(lst):
# 修改列表的内容
lst.append(4)
print("Inside function:", lst)
def reassign_list(lst):
# 重新赋值列表
lst = [10, 20, 30]
print("Inside function:", lst)
# 测试 modify_list 函数
my_list = [1, 2, 3]
print("Before calling modify_list:", my_list)
modify_list(my_list)
print("After calling modify_list:", my_list)
# 测试 reassign_list 函数
print("\nBefore calling reassign_list:", my_list)
reassign_list(my_list)
print("After calling reassign_list:", my_list)
输出结果如下:
Before calling modify_list: [1, 2, 3]
Inside function: [1, 2, 3, 4]
After calling modify_list: [1, 2, 3, 4]
Before calling reassign_list: [1, 2, 3, 4]
Inside function: [10, 20, 30]
After calling reassign_list: [1, 2, 3, 4]
Example—传递不可变对象
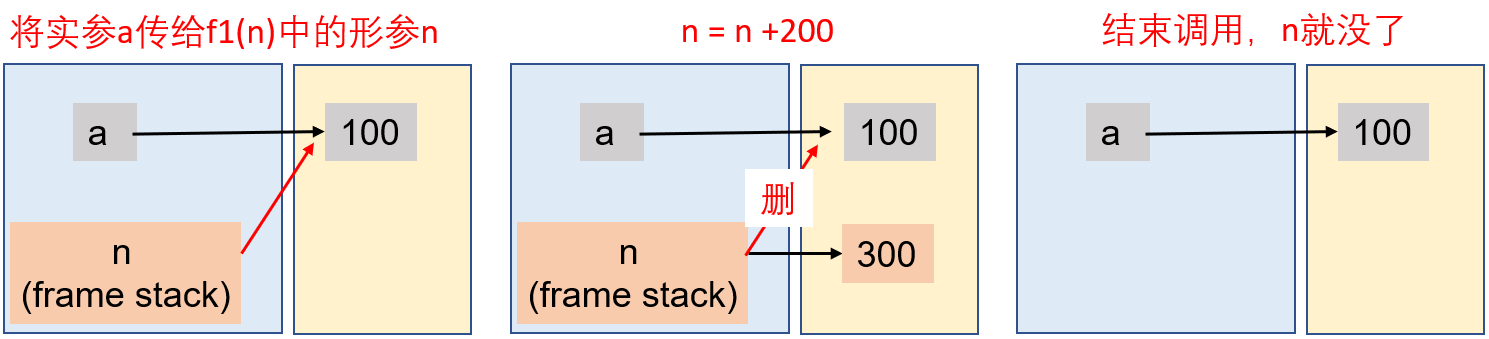
a = 100
def f1(n):
print("n:",id(n)) # 传递进来的是a对象的地址
n = n+200 # 由于a是不可变对象,因此创建新的对象n
print("n:",id(n)) # n 变成新的对象
print(n)
f1(a)
print("a:",id(a))
print(n) # 这句会报错,因为函数中引入的n是局部变量,用完就被垃圾回收了传递不可变对象时,不可变对象里面包含的子对象是可变的,则方法内修改这个可变对象,源对象也会发生变化。
a = (10, 20, [5, 6])
print("a:", id(a))
def tet01(m):
print("m", id(m))
m[2][0] = 888
print(m)
print("m:", id(m))
tet01(a)
print(a)
# a: 2516431479488
# m 2516431479488
# (10, 20, [888, 6])
# m: 2516431479488
# (10, 20, [888, 6])
位置/默认值/命名/可变参数
位置/默认值/命名参数:部分参数提供默认参数,那么这些参数必须在末尾。
# coding:utf-8
# 位置参数
def f1(a, b, c):
print(a, b, c)
f1(2,3,4)
f1(2,3) #报错,位置参数不匹配
# 默认值参数
def f2(a,b, c=10, d=20) # 默认值必须位于普通参数之后
print(a,b,c,d)
f2(8,9)
f2(8,9,19)
f2(8,9,19,29)
# 命名参数
def f3(a,b,c):
print(a,b,c)
f3(8,9,19) # 位置参数
f3(c = 10, a = 20, b = 30) # 命名参数,输出20 30 10
可变参数:可变参数指的是“可变数量的参数”,可以实现更灵活的参数传递方式,分两种情况:
1. func(*args) ,将多个参数收集到一个“元组”对象中。
- 调用时的参数会存储在一个tuple对象中,赋值给形参;
- tuple是有序的,所以args中元素的顺序受到赋值时的影响;
2. func(**kwargs) 将多个参数收集到一个“字典”对象中。
- 是把参数以键值对字典的形式传入;
- kwargs是keyword arguments的缩写;
- 字典是无序的,所以在输出的时候,并不一定按照提供参数的顺序;
- 同样在调用时,参数的顺序无所谓,只要对应合适的形参名就可以了;
- 不受参数数量、位置的限制;
注意:在带星号的“可变参数”后面增加新的参数,必须在调用的时候“强制命名参数”。
def f1(a, b, *c):
print(a, b, c)
f1(8,9,19,20)
# 8 9 (19, 20)
def f2(a,b,**c):
print(a, b, c)
f2(8, 9, name='gaoqi', age=18)
# 8 9 {'name': 'gaoqi', 'age': 18}
def f3(a,b,*c,**d):
print(a, b, c, d)
f3(8,9,20,30,name='gaoqi', age=18)
# 8 9 (20, 30) {'name': 'gaoqi', 'age': 18}
# 利用元组传递参数
def calSum(*args):
sum = 0
for i in args:
sum += i
print(sum)
calSum(1,2,3) #输出 6
calSum(123,456) #输出 579
calSum() #输出 0
# 利用字典传递参数
def printAll(**kwargs):
for k in kwargs:
print(k, ":",kwargs[k]) # k表示key, kwargs[k]表示key对应的value
printAll(x=4, y=5)
# 输出
"""
x : 4
y : 5
"""
输入参数不足:匹配能匹配的部分,其他的输出默认值
# coding: utf-8
def func(arg1=1, arg2=2, arg3=3):
print(arg1, arg2, arg3)
func(2, 3, 4) # 输出 2 3 4
func(5, 6) # 输出 5 6 3
func(7) # 输出 7 2 3
func(arg2=8) # 指定参数值,输出 1 8 3
func(arg3=9, arg1=10) # 指定参数值,输出10 2 9
func(arg1=13, 14) # 指定参数,错误用法,指定的要放后面
func(15, arg1=16) # 指定参数,错误用法,不能指定同一个
三种调用方式混合在一起的例子
变量作用域-LEGB规则
【局部变量】(Local variable)
- print(locals()) 输出所有的局部变量;
- 如果不用global声明的话,def里面的参数都是局部变量;
- 在函数内部定义的变量;
- 不同的函数可以有相同的变量名,不会产生影响;
- 它的作用是临时保存函数中的数据,函数被执行完,该数据就没有了,每次调用该函数,就会形成一个新的【栈帧】(stack frame),函数运行完一次,这种栈帧就被丢掉,类似胶卷一样,栈帧也是有栈和堆;
- 如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量;
- 局部/全局变量效率对比: 局部变量的查询和访问速度比全局变量快,优先考虑使用,尤其是在循环的时候。在特别强调效率的地方或者循环次数较多的地方,可以通过将全局变量转为局部变量提高运行速度,但是大部分情况下不需要关注效率。比如def xx里面循环1000000次计算sqrt(30),import math得到的math就是全局变量,然后每次计算都用math.sqrt(30)即每次都是访问全局变量;但是如果在循环计算之前令b = math.sqrt,然后每次计算直接用b(30),那么就是访问局部变量,速度更快。
【全局变量】(global variable)
- print(globals()) 输出所有的全局变量;
- 在函数外部定义的变量;
- 全局变量的使用降低了函数的可读性和通用性,尽量避免使用;
- 对于不可变类型的全局变量,要在函数内修改,需要使用global时修改全局变量;
- 对于可变类型的全局变量,不使用global时,也可以在函数内进行修改;
- 注:
- 可变对象:字典、列表、集合、自定义的对象等;
- 不可变对象:数字、字符串、元组、function 等;
下面的例子展示变量的作用域:注意例子2中的全局变量。另外调用函数,最好写成显式,例子2中的func()这种写法就不太好。
# example_1 变量x的值在函数内容发生改变,但是并不传递到函数外
def func(x):
print("x in the beginning of func(x): ", x)
x = 2
print("x in the end of func(x): ", x)
x = 50
func(x)
print("x after calling func(x): ", x)
# 输出
"""
x in the beginning of func(x): 50
x in the end of func(x): 2
x after calling func(x): 50
"""
# example_2 函数内部定义了全局变量,于是将赋值后的x传递到函数之外
def func():
global x
print("x in the beginning of func(x): ", x)
x = 2
print("x in the end of func(x): ", x)
x = 50
func()
print("x after calling func(x): ", x)
# 输出
"""
x in the beginning of func(x): 50
x in the end of func(x): 2
x after calling func(x): 2
"""
nonlocal 关键字
nonlocal——用来声明外层的局部变量
global——用来声明全局变量
Python 3.9包含的关键字:['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
# coding: utf-8
# 测试 nonlocal、global 关键字的用法
a = 100
def outer():
b = 10
def inner():
nonlocal b # 声明外部函数的局部变量
print("inner b:", b) # 如果没有nonlocal b,那么只能读取b但是不能修改
b = 20
global a # 声明全局变量a = 1000
inner()
print("outer b:", b)
outer()
print("a:", a)
""" 输出:
inner b: 10
outer b: 20
a: 100
"""
LEGB 规则
查找名称的优先顺序:Local-->Enclosed-->Global-->Built in
Local——指的就是函数或者类的方法内部
Enclosed——指的是嵌套函数(一个函数包裹另一个函数,闭包)
Global——指的是模块中的全局变量
Built in——指的是 Python 为自己保留的特殊名称。
如果某个 name 映射在局部(local)命名空间中没有找到,接下来就会在闭包作用域(enclosed)进行搜索,如果闭包作用域也没有找到,Python 就会到全局(global)命名空间中进行查找,最后会在内建(built-in)命名空间搜索 (如果一个名称在所有命名空间中都没有找到,就会产生一个 NameError)。
匿名函数—lambda
【匿名函数】(anonymous function):在Python中,匿名函数是没有定义名称的函数。虽然def在Python中使用关键字定义了普通函数,但使用关键字定义了匿名函数lambda。因此,匿名函数也称为【lambda函数】,其特点如下:
- Lambda函数可以具有任意数量的参数,但只能有一个表达式,表达式被求值并返回;
- lambda表达式能表达的逻辑很有限,能用lambda的地方其实都可以用def替代,只是前者更简洁,但是能用def的地方,不一定能用lambda;
- lambda表达式虽然简洁,但是它的主体只能是一个表达式,不可以是代码块,甚至不能是命令,比如不能使用print命令;
- lambda 表达式的语法格式: lambda 参数列表: 表达式
# 匿名函数lambda的使用示例
sum = lambda a,b,c: a+b+c
print(sum(1,2,3)) # 输出 6
# 等价于下面的有名函数
def sum(a,b,c):
return a+b+c
print(sum(1,2,3))
# lambda位于有名函数里面的例子
def fn(x):
return lambda y: x+y
a = fn(2) # 得到 2+y
print(a(3)) # y=3, 于是2+3 =5,即输出5
# 关于lambda更复杂的例子
g = [lambda a:a*2,lambda b:b*3,lambda c:c*4]
print(g[0](6),g[1](7),g[2](8)) #输出 12 21 32
返回值
函数体中return:
def test():
print("abdc")
return # 两个作用,返回值;结束函数执行
print("def") #在return之后,所以不被执行
test() # 只输出abd- 两个作用:
- 执行并返回值
- 结束函数,即使return后面还有其他语句也不再继续执行
- 如果函数体中不包含return语句,则返回None值
- 要返回多个返回值,使用列表、元组、字典、集合将多个值"存起来"即可
递归函数
【递归函数】(General recursive function):自己调用自己的函数,在函数体内部直接或间接的自己调用自己,类似数学归纳法。 每个递归函数必须包含两个部分:
1. 终止条件
表示递归什么时候结束。一般用于返回值,不再调用自己。
2. 递归步骤
把第 n 步的值和第 n-1 步相关联。
递归函数由于会创建大量的函数对象、过量的消耗内存和运算能力。在处理大量数据时,谨慎使用。
# coding: utf-8
# 测试递归函数的基本原理
def test01(n):
print("test01:", n)
if n == 0:
print("over")
else:
test01(n-1)
print("test01***", n)
test01(4)
"""# 输出
test01: 4
test01: 3
test01: 2
test01: 1
test01: 0
over
test01*** 0
test01*** 1
test01*** 2
test01*** 3
test01*** 4
"""
嵌套函数
【嵌套函数】(Nested function): 在函数内部定义的函数!应用场景:
- 封装(Encapsulation) —— 数据隐藏,外部无法访问嵌套函数;
- 贯彻DRY(Don't Repeat Yourself)原则,嵌套函数可以让我们在函数内部避免重复代码;
- 闭包 —— 后面会详细解释
# 嵌套函数的定义
def outer():
print("outer running")
def inner01():
print("inner01 running")
inner01() # 在outer里面调用inner
outer()
# 输出outer running
# inner01 running
# 例子-使用嵌套函数避免重复代码
# 修改前
def printChineseName(name,familyName):
print("{0} {1}".format(familyName, name))
def printEnglishName(name,familyName):
print("{0} {1}".format(name, familyName))
# 修改后——使用 1 个函数代替上面的两个函数
def printName(isChinese,name,familyName):
def inner_print(a, b):
print("{0} {1}".format(a, b))
if isChinese:
inner_print(familyName, name)
else:
inner_print(name, familyName)
printName(True,"小七","高") # 输出 高 小七
printName(False,"George","Bush") # 输出 George Bush
注释和Debug
注释
- 一般不要在代码里面写中文注释,如果非要写,请在第一行输入# coding: gbk
- Ctrl+/ 注释某一行,三个键一起,再作用一次就接触注释
- 注释某一段:使用三个单/双引号。选中内容,然后按住Shift不放,然后连续敲击三次引号键。参见这里。
# 注释功能 """ 这是我的python第一课 我学习了基本语法和常用运算符 """ # 换行输出功能 print("""这是我的python第一课 我学习了基本语法和常用运算符""" )
排错和调试
- python shell
三个右括号 >>> 是 python 输入的提示符,它表示 python 解释器已经准备好了,等待你的命令。
python shell 可以非常方便的运行 python 语句,这一点对调试、快速组建和测试相当有用。当你在编写代码的过程中,对一些方法不确定的时候,可以通过 python shell 来进行试验。 - 查询
- 某个对象的物理地址:id(变量名/obj)
- 查询对象的类: type(obj)
- 输出obj中储存的数据:print(obj)。
- debug方法1 —— 选中某一行(左侧出现红点) 然后右键debug,接着可以使用step over/step into 来陆续执行每一行代码,另外还有step out(三者区别见这里)。如果我们选中两行,也就是左侧设定两个红点thread,debug的时候先执行到第一个红点处,然后我们点“run to cursor”就会直接从第一个红点处执行到第二个红点处,参见视频。
- debug方法2 —— 每生成一次变量,让这个变量输出一次,看程序循环到哪里就循环不动了。下面分别给出原程序和改造之后的程序(输出调试信息)
# original one import random a =0 for i in range(5): b = random.choice(range(5)) a +=i / b print(a) # revised one import random a = 0 for i in range(5): print("i: %d" % i) b = random.choice(range(5)) print("b: %d" % b) a +=i / b print("a: %d" % a) print() print(a) - 调出帮助文档:直接在pycharm界面按F1的话,出现的是pycharm网页的帮助文档。选中自己编写的某个代码使用的函数,选鼠标选中后,左手按住Ctrl,右手单击一下;或者先选中后,然后按shift+F1。
- 异常处理( try…except )
除去开发者可以避免的错误,使用者可能输入一些非法值,这个时候就必须给出响应的“反馈”,常用的是try....except语句,比如打开一个本身就不存在的文件:文件存在,被打开,给出“回应”;文件不存在,同样要给出“回应”。总之,程序员的程序给用户用,必须考虑到所有情况。
try:
f = open("non-exist.txt")
print("File opened!")
f.close()
except:
print("File not exists.")
print("Done")
文件操作和输出格式
文件操作
# coding: gbk
# with的用法
with open("data.txt") as file:
file.read()
# read
f = open('任缥缈.txt', encoding= 'utf-8') #中文的编码 ,打开文件
s = f.read() #读取文件
print(s) # 输出内容
f.close() # 关闭文件
# write
f = open('write_test.txt', mode = 'w', encoding = 'utf-8') # w表示写入, 生成新文件
f.write('我很好\n')
f.write('你好吗\n')
f.close()其他补充:
- readline() ——读取一行内容
- readlines()——把内容按行读取至一个list中
- 上面的mode='w'可以删除mode =,效果一样;如果选择'w'模式就不能read了,写入模式下会删除先前的内容;如果write的文件不存在,那么会自动创建一个文件;默认是阅读模式,即'r',如果文件不存在,则会出现异常;如果想不删除以前的内容而进行写入,那么选择'a' 模式(appending);如果是记事本输入的,那么‘utf-8’就该变成‘gbk’,如果是浏览器内复制的,那么就是‘utf-8’(浏览器的中文编码多使用 utf-8)
with的用法——在Python中,'with'语句用于简化资源管理和异常处理。'with'语句创建了一个上下文管理器,它可以在代码块执行前进行一些准备工作,并且在代码块执行完毕后进行清理工作。'with'语句的基本语法是 'with expression as variable:',其中 'expression' 是一个上下文管理器对象,'variable' 是一个变量,用于存储上下文管理器的返回值。当代码块执行完毕或者发生异常时,上下文管理器的'__exit__'方法会被调用,用于执行清理工作。这样可以确保资源得到正确地释放,而不需要显式地调用关闭资源的方法。
对于文件操作,read或者write之后不用再close,因为with块代码执行完毕后自动关闭资源。
输出
\ 被称作【转义字符】,用处如下:
- 换行 \n
- 横向制表符 \t 表示字符串中的制表符(相当于按一下tab键的效果)
- 续行符 \(在行尾时)
print("tiantian\
xiangshang")
#输出 tiantian xiangshang (同一行) - 反斜杠符号 \\
- 单引号 \'
- 退格 \b
- 字符串里面有引号,那么在每个引号之前加上\,程序就可以区分不同引号(a = (' He said, \"I\'m yours!\" ' ))
\t 被称作【制表符】(Box Drawing)
作用是在不使用表格的情况下在垂直方向按列对齐文本。类似word TAB
例子: result = '%s \t: %d\n' % (data[0], sum)
% 对字符串进行格式化,其中%d 替换整数,%f 替换小数,%.2f替换保留两位小数,%s 替换字符串。例子:
- print('My age is %d' % 18)
- print('Price is %f' % 4.99)
- name = 'Crossin'
print('%s is a good teacher.' % name) - print("%s's score is %d" % ('Mike', 87)),一个字符串里面替换两个,这里的('Mike', 87)就是元组
- 数字字符串化 print('My age is ' + str(18)),或者print("My age is", str(18))
【format 函数】format函数是用来替代前面的%的,它可以接受不限个数的参数,而且位置可以不按顺序。
# format指定顺序
a = "我叫{0},我今年{1}岁了,我的专业是{2}。"
print(a.format("呼哨","25","材料科学与工程"))
# format不指定顺序
a = "我叫{name},我今年{age}岁了,我的专业是{major}。老师说{name}成绩一般。"
print(a.format(major= "材料科学与工程", name="呼哨", age=18))
# format数字格式化
a = "我是{0},我的存款有{1:.2f}"
print(a.format("高淇",3888.234342))
#输出:我是高淇,我的存款有3888.23
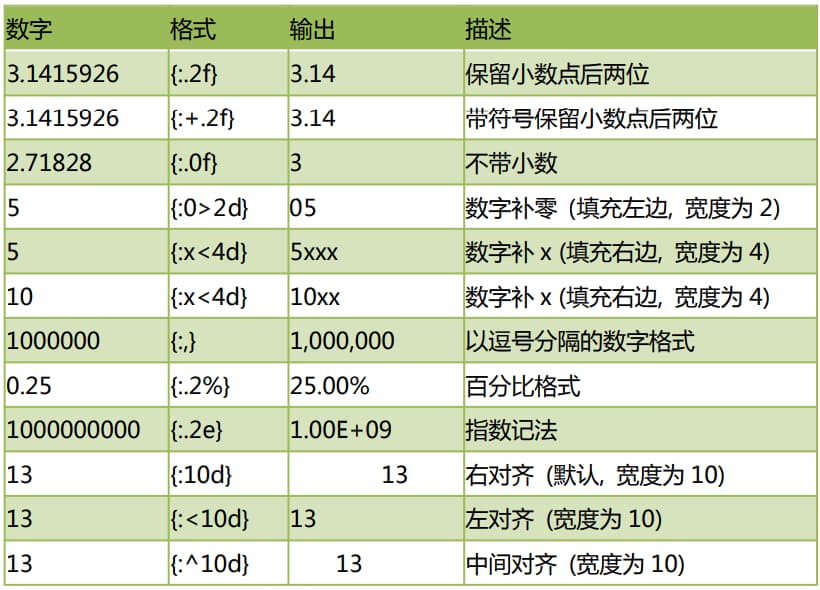
format填充与对齐(排版)
^、<、>分别是居中、左对齐、右对齐,后面带宽度
:号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充 。
例子1:
"{:*>8}".format("245")
得到 '*****245'
{:*>8}表示右对齐,8表示占据8个位置,由于我们只有一个三位数,所以左侧的5个位置由我们制定的*来占据。
例子2:
"我是{0},我喜欢数字{1:*^8}".format("高淇","666")
得到'我是高淇,我喜欢数字**666***'
另外的方法是center()、ljust()、rjust()这三个函数用于对字符串实现排版。

其他
- 不换行打印
end=' ' 输出一个之后,空格,输出第二个。end 参数的作用是指定 print 结束之后的字符,默认是回车。你可以试试设置成不同字符的效果。 - 输出一个变量的数据类型
比如a = 1,然后print(a, type(a))得到的是1 <class 'int'>,这里的int可以变为字符串str、bool类型等。 - 错误的print方式
print('Hello'+1) 或者print('hello%d' % '123')
前者的错误原因:加号只能用于数字之间或者字符串之间;%d对应的是数字,而不是字符串,加上引号的数字就变成了字符串。
其他
迭代器与生成器
cd命令
- 在terminal输入python 并敲下回车,就可以进入python环境了;
- C:\Users\hujie>dir 输入dir得到当前文件夹下所有子文件的信息;
- 输入cd 得到目录名;
- 输入cd.. 返回到上一级目录;
- 输入cd 目录名, 进入当前目录的子目录。
注:dir-directory(目录);cd-change directory(改变目录)
python 2和3
- print('this is version 3') , 而2中不需要括号(3中print是一个函数,所以有括号);
- python 2和3的不换行输出
python 2:print '*',
python 3:print('*', end=' ') # python每次print默认以换行结束,这里使用end,将换行结束变成了空格结束。 - 后续碰到了再补上,学习别人的程序,要搞清楚是2还是3。
命名习惯(约定俗成)

name变量
python代码既可以作为一个脚本被执行,也可以作为一个模块被引入(相当于定义的函数),有时候我们只想在它作为一个脚本被执行的时候执行一些代码,这就需要判断 __name__ 变量(前后各有两个下划线)的值。作为python的内置变量,它是每个python模块必备的属性,但是它的值取决于你是如何执行这段代码的。
if __name__ == '__main__': 可以判断代码是作为脚本被执行还是作为模块被引入:- 当你直接执行一段脚本的时候,这段脚本的 __name__ 变量等于 __main__ ,当这段脚本被导入其他程序的时候, __name__ 变量等于脚本本身的名字;
- 在hello.py里面写入print(__name__),当它被直接执行时,输出的是__main__;但是在Python Console引入该py文件,即import hello得到的是hello,而不是__main__。
实际应用的例子:在大的项目开发中,一般会尽量将一个完整的项目进行模块化,也就是拆成很多个模块文件,为了保证每个模块都能正常运行,我们就可以在这个模块下面使用if __name__ == '__main__',等于对它进行单独测试,如果没有问题了,我么就可以正常数使用了。每一个模块都能单独正常运行,那么最后再测试整个项目(我:类似脚本里面引入了各种模块)。
参考资料:
(0) python神奇的if __name__=="__main__" (推荐)
(1) 100秒学会Python中的 if __name__ == '__main__':
(2) 『if __name__ == "__main__"』到底啥意思
(3) Python 的 __name__ 变量,到底是个什么东西?
模块
模块化编程的优势:
1. 便于将一个任务分解成多个模块,实现团队协同开发,完成大规模程序
2. 实现代码复用。一个模块实现后,可以被反复调用
3. 可维护性强
模块可以理解为是一个包含了函数和变量的py文件。在你的程序中引入了某个模块,就可以使用其中的函数和变量。 from 模块名 import 方法名
random模块
import random就是导入random模块,但是这个模块里面有很多种类的函数,我们必须选择需要的进行调用,比如random.randint(1, 10) 和random.choice([1, 3, 5])。
查找random模块的所有函数:在terminal窗口输入python回车,然后输入 import random回车然后输入dir(random)即可显示出该模块(库)包含的所有函数。
- 用法举例: 比如 from random import randint(引入随机数模块),接下来你就可以用randint来产生随机数,比如num = randint(1, 100)
- random.randint(a, b)可以生成一个a到b间的随机整数,包括a和b。注:a、b必须都是整数。
- random.randint(3, 3) 结果只有3。
- random.random() 生成一个随机浮点数[0.0, 1.0)左边闭合,右边开。
- random.uniform(a, b)生成a、b之间的随机浮点数。不过与randint不同的是,a、b无需是整数,也不用考虑大小。
- random.choice(seq)
- random.choice([1, 2, 3, 4, 5, 7, 13]) #list
- random.choice("hello") #字符串
- random.choice(["hello", "world"]) #字符串组成的list
- random.choice((1, 2, 3)) #元组
- random.randrange(start, stop, step)
- random.sample(population, k) 从population序列(list、元组、字符串)中,随机获取k个元素,生成一个新序列。sample不改变原来序列。
- random.shuffle(x) 把序列x中的元素顺序打乱。shuffle直接改变原有的序列
注:在电脑模拟中伪随机数用来模拟产生随机的过程,因而得到的随机数不是真正的随机数。伪随机数的一个特别大的优点是它们的计算不需要外部的特殊硬件的支持,因此在计算机科学中伪随机数依然被使用(可以选取不同的)。真正的随机数必须使用专门的设备,比如热噪信号、量子力学的效应、放射性元素的衰退辐射,这些是完全不可预测的,而伪随机数实际上是可以预测的。
math模块
官方文档
使用之前import math,然后按需求选择math里面特定的函数。比如要想输出pi, 就要import math,然后调用math.pi,即输出print(math.pi)。有的时候有简写,比如通过from...import...指明from math import pi 然后print (pi)注意math中的pi(math.pi)已经被重命名为pi,为了避免歧义,可以写成from math import pi as math_pi然后print (math_pi)。下面列举几个常用的:
- math.pi # 圆周率π
- math.e # 自然常数
- math.ceil(x) # 对x向上取整
- math.floor(x) # 对x向下取整
- math.pow(x,y) # 指数运算
- math.log(x) # 对数,默认基底为e
- math.sqrt(x) # 平方根
- math.fabs(x) # 绝对值
- math.sin(x)
- math.degrees(x) # 弧度转角度
- math.radians(x) # 角度转弧度
time模块
【unix时间戳】计算机领域的特殊事件epoch,它表示的时间是1970-01-01 00:00:00 UTC
time.time()返回的就是从epoch到当前的秒数(不考虑闰秒),这个值被称为unix时间戳。 对比labview的起始时间是1904年1月1日8点。
一段程序,首位都用 time.time() 获取一下时间,然后两个时间相减,就得到了程序运行消耗的时间。
import time
starttime = time.time()
print ('start:\%f' \% starttime)
for i in range(10):
print (i)
endtime = time.time()
print ('end:\%f' \% endtime)
print ('total time:\%f' \% (endtime-starttime))time.sleep(secs) 让程序暂停secs秒,类似于labview中的wait或者arduino中的delay。比如在抓取网页的时候,适当让程序sleep一下,可以减少短时间内的请求,提高请求的成功率。
常见函数
Zip
使用 zip()并行迭代,要使用zip,两种方法:p=list(d)或者p=dict(d),注意第二种字典的方法,zip里面只能包含两个(abc必须去掉一个)
# coding: utf-8
a = [10,20,30]
b = [40,50,60]
c = [70,80,90]
d = zip(a,b,c)
print(d,type(d))
# 输出 <zip object at 0x02D5D4B8> <class 'zip'>
names = ("高淇", "高老二", "高老三", "高老四")
ages = (18, 16, 20, 25)
jobs = ("老师", "程序员", "公务员")
# zip的写法
for name, age, job in zip(names, ages, jobs):
print("{0}--{1}--{2}".format(name, age, job))
# 非zip的写法
for i in range(3):
print("{0}--{1}--{2}".format(names[i],ages[i],jobs[i]))
""" 输出
高淇--18--老师
高老二--16--程序员
高老三--20--公务员
"""
eval 函数
- 将字符串 str 当成有效的表达式来求值并返回计算结果
- 适用场景:从客户端发来一段代码,或者从某个文件里读取的一段代码,可以通过eval函数执行
语法: eval(source[, globals[, locals]]) -> value
注意:eval 函数会将字符串当做语句来执行,因此会被注入安全隐患。比如:字符串中含有删除文件的语句,那就麻烦大了,因此使用时候要慎重。
# 例子-1
s = "print('abcde')"
eval(s) # 输出 abcde
# 例子-2
a = 10
b = 20
c = eval("a+b")
print(c) # 输出 30
# 例子-3
dict1 = dict(a=100,b=200)
d = eval("a+b",dict1)
print(d) # 输出 300
xxx
参考资料:
(1) 高阶函数—廖雪峰
(2) 一文搞懂python的map、reduce函数—知乎
reverse函数
作用是将一个列表颠倒过来。比如:
a=[1,2,3,4]
b=a.reverse()
print(b) # 返回None
print(a) #返回[4, 3, 2, 1]
所以正确的写法就是:
a=[1,2,3,4]
a.reverse()
print(a)
a=[1,2,3,4]
print(id(a)) # 输出33651448
a.reverse()
print(id(a)) # 地址不变 输出33651448
b=reversed(a)
b = list(b)
print(b) # [1, 2, 3, 4]
print(b) # [1, 2, 3, 4]
b=reversed(a) # 返回迭代器,指针不断移动
print(list(b)) # [1, 2, 3, 4]
print(list(b)) # [] 因为第一次已经遍历完了
reverse和之前讨论的sort类似。
enumerate函数
就是labview中常见的枚举,enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
aa=["a","b","c","f","a"]
print(enumerate(aa)) # 输出 <enumerate object at 0x01C066C0>
print(list(enumerate(aa))) # 输出[(0, 'a'), (1, 'b'), (2, 'c'), (3, 'f'), (4, 'a')]
# 用枚举
aa = ['a', 'b', 'c', 'f', 'a']
for index,s in enumerate(aa):
if s== "a":
print(index)
# 如果用老方法
aa = ['a', 'b', 'c', 'f', 'a']
bb = 0
for x in aa:
if x == "a":
print(bb)
bb += 1
map函数
map()是python的内置函数,会根据提供的函数对指定序列(如列表、元组等)做映射。并通过把函数f依次作用在序列的每个元素上,得到一个新的list并返回。map()函数不改变原有的序列,而是返回一个新的序列。
格式 map(function_to_apply, list_of_inputs)
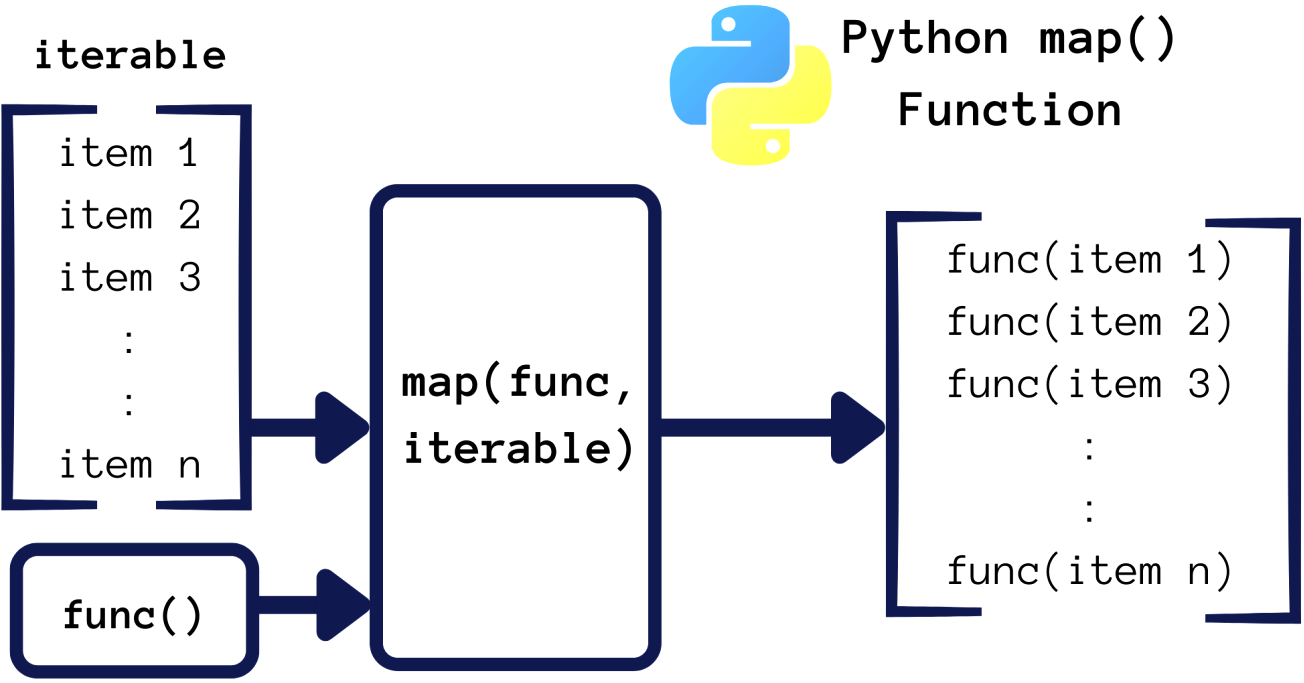
# example_1 将list中的字符型的数字,转换成int
a = list("1213456789")
print(a) # ['1', '2', '1', '3', '4', '5', '6', '7', '8', '9']
b = map(int, a)
print(b) # <map object at 0x018EF8B0>
print(type(b)) # <class 'map'>
print(list(b)) # [1, 2, 1, 3, 4, 5, 6, 7, 8, 9]
# example_2 将数字的list中的每个数字都平方一下
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
def f(x):
return x*x
b = map(f, a)
print(list(b)) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
# example_3 两个或者多个list的情况
a = map(lambda x,y:x**y,[1,2,3],[1,2,3])
print(a) # <map object at 0x01805E70>
print(list(a)) # [1, 4, 27]
# example_4 func不仅只接收函数,同样可接收lambda表达式
a = [1, 2, 3, 4]
b = map(lambda x: x*x, a)
print(list(b)) # [1, 4, 9, 16]x
reduce 函数
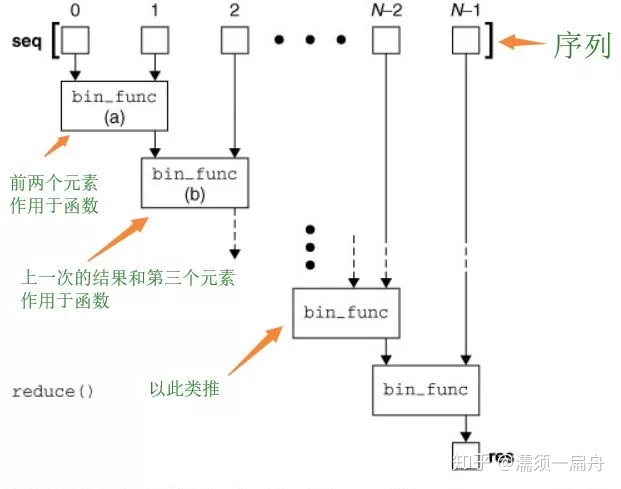
reduce的工作过程是 :在迭代序列的过程中,首先把 前两个元素(只能两个)传给 函数,函数加工后,然后把 得到的结果和第三个元素 作为两个参数传给函数参数, 函数加工后得到的结果又和第四个元素 作为两个参数传给函数参数,依次类推。
# 计算加和
from functools import reduce # reduce函数不能直接使用,必须先import
def add(x, y) : # 两数相加
return x + y
a = [1,2,3,4,5]
sum1 = reduce(add,a) # 计算列表和:1+2+3+4+5
print(sum1)
sum2 = reduce(add,a,10) # 10作为出初始参数
print(sum2) # 计算列表和:1+2+3+4+5+10
#计算阶乘,两种方法
from functools import reduce
n = 5
print(reduce(lambda x, y: x*y,range(1, n+1))) # 输出120
from functools import reduce
def f(x, y):
return x*y
n = 5
items = range (1, n+1)
factorial = reduce(f, items)
print(factorial) # 输出120