线性代数中的微分方程
线性代数的基本图像(The big Picture of Linear Algebra)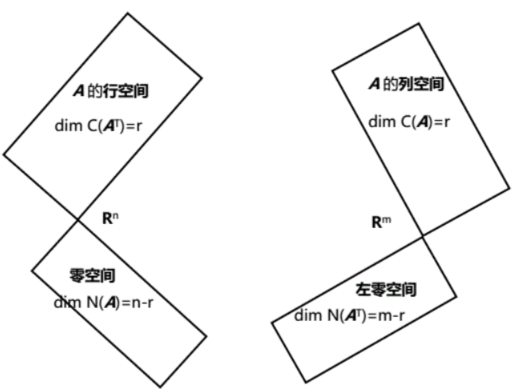
图(Graphs)
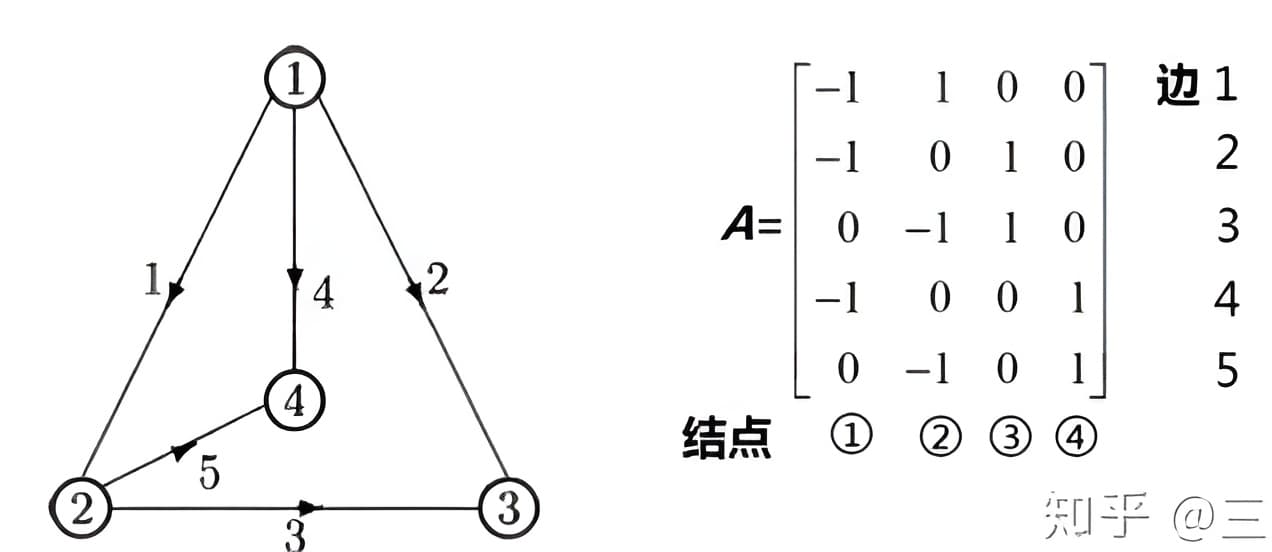 本土并不是“完全图”,完全图中所有的结点都和其它的结点相连,但是通常情况下并不满足这种情况。对互联网结构进行描述就是这种“图”的重要应用之一,其它可以用“图”描述的例子还包括电话网络和神经网络等等。
本土并不是“完全图”,完全图中所有的结点都和其它的结点相连,但是通常情况下并不满足这种情况。对互联网结构进行描述就是这种“图”的重要应用之一,其它可以用“图”描述的例子还包括电话网络和神经网络等等。
电势差(电流的源动力):$$A \mathbf{v}=\left[\begin{array}{rrrr} -1 & 1 & 0 & 0 \\ -1 & 0 & 1 & 0 \\ 0 & -1 & 1 & 0 \\ -1 & 0 & 0 & 1 \\ 0 & -1 & 0 & 1 \end{array}\right]\left[\begin{array}{l} v_{1} \\ v_{2} \\ v_{3} \\ v_{4} \end{array}\right]=\left[\begin{array}{l} v_{2}-v_{1} \\ v_{3}-v_{1} \\ v_{3}-v_{2} \\ v_{4}-v_{1} \\ v_{4}-v_{2} \end{array}\right]$$
电流KCL:$$A^{T} \mathbf{w}=0$$矩阵\( A \)给出的是电势差,即食物发生的驱动力,矩阵\( A^{T}\)给出的是平衡方程,在这里可以解释为结点处的电流平衡。而最终我们要将两个方程结合,即将两个矩阵结合起来,这就是图论的核心内容,即矩阵\( A^{T}A \),它被称之为图的拉普拉斯方程。这部分内容是离散应用数学最基础也是最重要的内容。
图的关联矩阵(Incidence Matrices of Graphs)
补充
特征值和特征向量
这里讲的特征值和特征向量都是将其放在微分方程组来理解的,只要微分方程组时线性的,那么就很容易用线性代数的方式描述。
微分方程组\(\displaystyle\frac{d \mathbf{y}}{d t}=\boldsymbol{A} \mathbf{y} \)由\( n\)个线性方程组成,矩阵\(\boldsymbol{A} \)为\( n \)阶矩阵。对应于这种形式的微分方程,解的形式为\( \mathbf{y}(t)=e^{\lambda t} \mathbf{x} \),其中\( \mathbf{x} \)为向量,但是与\( t\)的改变无关,是矩阵\( \boldsymbol{A}\)的特有的“属性向量”,解函数与\( t\)的所有的关系都在\( e^{\lambda t} \)中。将解函数回代,得到$$\lambda e^{\lambda t} \mathbf{x}=\boldsymbol{A} e^{\lambda t} \mathbf{x}$$消去指数项,得到\( \boldsymbol{A} \mathbf{x}=\lambda \mathbf{x}\),于是转化成我们传统的特征值和特征向量的求解。需要说明的是,\( \mathbf{x}\)不能是零向量,否则都没意义了,而特征值\( \lambda \)可以是实数也可以是复数。
例子:应用特征值和和特征向量求解微分方程组\( \begin{aligned} &y^{\prime}_{1}=5 y_{1}+y_{2}\\ &y^{\prime}_{2}=3 y_{1}+3 y_{2} \end{aligned} \)求解得$$\mathbf{y}(t)=\left[\begin{array}{l} y_{1}(t) \\ y_{2}(t) \end{array}\right]=c_{1} e^{6 t}\left[\begin{array}{l} 1 \\ 1 \end{array}\right]+c_{2} e^{2 t}\left[\begin{array}{c} 1 \\ -3 \end{array}\right]$$解函数中的两个向量是特征向量,其对应的指数项上\( t \)前面的系数\( \lambda \)就是对应的特征值。利用初始条件\( \mathbf{y}(0)=c_{1}\left[\begin{array}{l} 1 \\ 1 \end{array}\right]+c_{2}\left[\begin{array}{c} 1 \\ -3 \end{array}\right]\)可以确定参数\(c_{1} \)和\( c_{2}\)。
性质:\( \boldsymbol{A}^{n} \mathbf{x}=\lambda^{n} \mathbf{x}\), \( (\boldsymbol{A}+\boldsymbol{c} \boldsymbol{I})\mathbf{x}=\lambda \mathbf{x}+c \mathbf{x}=(\lambda+c) \mathbf{x} \)
注意:这里并不是采用直接解耦的方式求解的,线性代数那门课上GS是用对角化解耦的方式求解的;但是本质来讲,这里也是一种不是很直观的特殊解耦,其实求出两个特征向量就是解耦的过程。
其实无论是矩阵的方幂次运算还是微分方程的求解,其本质都是统一的,最大的区别是前者是离散的,后者是连续的。特征值的性质在决定微分方程稳定性和方幂次运算结果的稳定性(无限多次运算)上是一致的,也就是说说如果我知道了特征值,那么我就可以判断对应微分方程的稳定性,而对应的离散的方幂次运算结果的稳定性和这个微分方程的稳定性是完全相同的。
求解\(\displaystyle\frac{d \mathbf{y}}{d t}=\boldsymbol{A} \mathbf{y}+\mathbf{F} \),其中\( \mathbf{F} \)为常数?
前面我们讨论的都是\( \mathbf{F}=0 \)的情况,换个写法就是$$\frac{d \mathbf{y}}{d t}-\boldsymbol{A} \mathbf{y}=0$$类似于我们求解线性代数中\( \boldsymbol{Ax}=\boldsymbol{b}\)的“零解”,那么按照线性代数的思路,求得零解之后需要找到一个特解。求解特解的思路很简单:如果向量解\(\mathbf{y} \)和时间\( t\)无关,那么$$\mathbf{0}=\boldsymbol{A} \mathbf{y}+\mathbf{F} $$很容易求得特解\( \mathbf{y_{p}}=-\boldsymbol{A} ^{-1}\mathbf{F}\),于是通解=零解+特解,即(以前面的例子为例)$$\mathbf{y}=c_{1} e^{6 t}\left[\begin{array}{l} 1 \\ 1 \end{array}\right]+c_{2} e^{2 t}\left[\begin{array}{c} 1 \\ -3 \end{array}\right]-\boldsymbol{A} ^{-1}\mathbf{F}$$
矩阵的对角化
Diagonalizing a Matrix
如果存在\( n \)个线性无关的特征向量,那么有:
\( \boldsymbol{A} \boldsymbol{V}=\boldsymbol{V} \boldsymbol{\Lambda}\,\Rightarrow \,\, \boldsymbol{A}=\boldsymbol{V} \boldsymbol{\Lambda} \boldsymbol{V}^{-1}\)
\( \boldsymbol{A}^{n}=\boldsymbol{V} \boldsymbol{\Lambda}^{n} \boldsymbol{V}^{-1}\) 特征向量不变,特征值进行方幂次运算。
矩阵的幂和马尔可夫矩阵
$$\mathbf{u}_{k}=\boldsymbol{A}^{k} \mathbf{u}_{0}=\boldsymbol{V} \boldsymbol{\Lambda}^{k} \boldsymbol{V}^{-1} \mathbf{u}_{0}=\boldsymbol{V} \boldsymbol{\Lambda}^{k} \mathbf{c}$$其中\( \mathbf{u}_{0}\)可以通过矩阵\( \boldsymbol{A} \)的特征向量的线性组合得到,而线性组合的系数矩阵\( \mathbf{c}=\boldsymbol{V}^{-1} \mathbf{u}_{0}\)得到。这种表示和下面的表示方法是等价的:$$\mathbf{u}_{k}=\boldsymbol{A}^{k} \mathbf{u}_{0}=c_{1} \lambda_{1}^{k} \mathbf{x}_{1}+c_{2} \lambda_{2}^{k} \mathbf{x}_{2}+\cdots+c_{n} \lambda_{n}^{k} \mathbf{x}_{n}$$
例子:\( \boldsymbol{A}=\left[\begin{array}{ll} 0.8 & 0.3 \\ 0.2 & 0.7 \end{array}\right] \),注意这是一个马尔科夫矩阵,矩阵中所有元素都是非负,列向量元素之和为\( 1 \)。求解得到$$\mathbf{u}_{k}=\boldsymbol{A}^{k} \mathbf{u}_{0}=c_{1} \lambda_{1}^{k} \mathbf{x}_{1}+c_{2} \lambda_{2}^{k} \mathbf{x}_{2}=c_{1} 1^{k}\left[\begin{array}{l} 0.6 \\ 0.4 \end{array}\right]+c_{2} 0.5^{k}\left[\begin{array}{c} 1 \\ -1 \end{array}\right]$$当\(k \)增大时,方程中的马尔科夫矩阵不断与自身相乘,这称之为马尔科夫过程。谷歌对网页的排序就是应用马尔科夫过程,在不停重复的过程中,观看次数多的主页其排序就会升高。等式的第二项很快变化至\( 0 \),而第一项则一直存在,它就是稳态。在我们的例子中,两个网页的最终排序值变为\( 0.6\)和\(0.4 \)。另外\(\boldsymbol{A}^{T} \)和\( \boldsymbol{A} \)具有相同的特征值,于是\( 1\)一定是马尔科夫矩阵的特征值之一。
马尔可夫矩阵中列向量元素加和为1,代表着没有流失掉什么或者创造出新东西,一切只是移动。到达终态时,两部分的比例就如稳态的特征向量所示。
解线性方程组(Solving Linear Systems)
前面讨论的是离散的,现在要讨论的是连续的情况,也就是用线性代数的方式描述随着时间连续变化的各个变量。求解\( n\)个常系数一阶微分方程组成的方程组\( \displaystyle\frac{d \mathbf{y}}{d t}=\boldsymbol{A} \mathbf{y} \)。线性方程组时相互耦合的,需要用特征值和特征向量表示方程组去解耦才能求解。这种耦合表现在,对于普通向量\( \mathbf{y} \),矩阵\( \boldsymbol{A} \)与之相乘其实就是混合\( \mathbf{y} \)中的元素,然后得到\( n \)个新的元素组成的向量的,即耦合过程。
假设矩阵\(\boldsymbol{A} \)中有\( n\)个特征值和\(\lambda_{i} \)个线性无关的特征向量\(\mathbf{x}_{i} \)满足\( \boldsymbol{A} \mathbf{x}_{i}=\lambda_{i} \mathbf{x}_{i}\)。如果有$$\mathbf{y}_{0}=c_{1} \mathbf{x}_{1}+c_{2} \mathbf{x}_{2}+\cdots+c_{n} \mathbf{x}_{n}$$则有\(\mathbf{y}(t)=c_{1} e^{\lambda_{1} t} \mathbf{x}_{1}+c_{2} e^{\lambda_{2} t} \mathbf{x}_{2}+\cdots+c_{n} e^{\lambda_{n} t} \mathbf{x}_{n}\)如果\( \mathbf{x}_{i}\)的实部为负数,那么时间久了,这一项就会衰减趋近\( 0 \),这和我们最开始讨论常系数二阶线性微分方程的稳定性是一致和统一的。
矩阵型指数(The Matrix Exponential)
这里介绍运用矩阵构造指数函数\( e^{A t}\)。
若有一个微分方程\(y^{\prime}=a y \),则其解为\( y(t)=e^{a t} y(0) \);
若有一个微分方程组\(\mathbf{y}^{\prime}=\boldsymbol{A} \mathbf{y} \),则其解向量\(\mathbf{y}(t)=e^{\boldsymbol{A} t} \mathbf{y}(0) \)。
矩阵型指数函数是通过级数构造出来的$$e^{\boldsymbol{A t}}=I+\boldsymbol{A} t+\frac{1}{2}(\boldsymbol{A} t)^{2!}+\frac{1}{3 !}(\boldsymbol{A} t)^{3}+\cdots$$其导数为$$\frac{d}{d t} e^{\boldsymbol{A} t}=\boldsymbol{A}+\boldsymbol{A}^{2} t+\frac{1}{2 !} \boldsymbol{A}^{3} t^{2}+\cdots=\boldsymbol{A} e^{A t}$$如果\( n \)阶矩阵\( \boldsymbol{A} \)具有\( n\)个线性无关的特征向量,那么对角化\( \boldsymbol{A}=\boldsymbol{V} \boldsymbol{\Lambda} \boldsymbol{V}^{-1} \),于是$$e^{\boldsymbol{A} t}=\boldsymbol{I}+\boldsymbol{V} \boldsymbol{\Lambda} \boldsymbol{V}^{-1} t+\frac{1}{2} \boldsymbol{V} \boldsymbol{\Lambda}^{2} \boldsymbol{V}^{-1} t^{2}+\cdots=\boldsymbol{V}\left(\boldsymbol{I}+\boldsymbol{\Lambda} t+\frac{1}{2} \boldsymbol{\Lambda}^{2}t^{2}+\cdots\right) \boldsymbol{V}^{-1}$$因此$$e^{A t}=\boldsymbol{V} e^{\Lambda t} \boldsymbol{V}^{-1}=\boldsymbol{V}\left[\begin{array}{ccc} e^{\lambda_{1} t} & & \\ & \ddots & \\ & & e^{\lambda_{n} t} \end{array}\right] \boldsymbol{V}^{-1}$$得到解函数\(\mathbf{y}(t)=e^{\boldsymbol{A} t} \mathbf{y}(0)=c_{1} e^{\lambda_{1} t} \mathbf{x}_{1}+c_{2} e^{\lambda_{2} t} \mathbf{x}_{2}+\cdots+c_{n} e^{\lambda_{n} t} \mathbf{x}_{n} \) 与这一解析式不同的是,应用矩阵型指数函数所得解函数公式即使在矩阵A不具有n个线性无关的特征向量时,仍然成立???。
矩阵型指数(The Matrix Exponential)
例子:\( \boldsymbol{A}=\left[\begin{array}{ll} 0 & 1 \\ 0 & 0 \end{array}\right]\)二重特征值\( \lambda_{1}=\lambda_{2}=0 \)。特征向量组成的空间就是矩阵的零空间,显然这个空间只需要一个向量就可以表示,于是该矩阵只有一个特征向量\( \mathbf{x}=\left[\begin{array}{l} 1 \\ 0 \end{array}\right]\)。
本例中,由于不具有\( 2 \)个线性无关的特征向量,因此不能通过特征向量的线性组合构造解函数,但是矩阵型指数函数的公式仍然适用,因为\(A^{2}=\left[\begin{array}{ll} 0 & 0 \\ 0 & 0 \end{array}\right] \),所以有\( e^{A t}=I+A t=\left[\begin{array}{ll} 1 & t \\ 0 & 1 \end{array}\right] \),后面高次项均为\( 0 \)。
本例中的矩阵非常简单,其对应方程为\( \begin{aligned}&y^{\prime}_{1}=y_{2}\\&y^{\prime}_{2}=0\end{aligned} \),求得\(y_{2}=C, y_{1}=C t \)。注意到矩阵型指数函数的矩阵中出现了一个\( t \),而通常不会出现这种情况,这和我们在微分方程中碰到重根,出现\(t e^{s t} \)的情况类似。
矩阵缺少两个特征向量的例子也是类似,例如\(\boldsymbol{A}=\left[\begin{array}{lll} 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{array}\right] \),则矩阵型指数函数为\( e^{A t}=\left[\begin{array}{ccc} 1 & t & \displaystyle\frac{1}{2} t^{2} \\ 0 & 1 & t \\ 0 & 0 & 1 \end{array}\right] \) 矩阵型指数函数不但给出了微分方程组解函数的简洁表达式,并且其表达式在特征向量缺失的情况下仍然适用。
相似矩阵
如果矩阵\( \boldsymbol{A}\)和\( \boldsymbol{B} \)满足\( \boldsymbol{B}=\boldsymbol{M}^{-1} \boldsymbol{A} \boldsymbol{M} \),其中\( \boldsymbol{M} \)为可逆矩阵,那么我们就称两个【矩阵相似】。相似矩阵具有相同的特征值\( \lambda\),如果矩阵\(\boldsymbol{B} \)的特征向量为\( \mathbf{x} \),那么矩阵\( \boldsymbol{A} \)的特征向量为\( \boldsymbol{M}\mathbf{x} \)。
例子:矩阵\( \boldsymbol{A}=\left[\begin{array}{ll} 2 & 3 \\ 0 & 4 \end{array}\right] \),其特征值为\(2 \)和\( 4\)。
(1) 矩阵\(\boldsymbol{A} \)和对角阵\( \left[\begin{array}{ll} 2 & 0 \\ 0 & 4 \end{array}\right]\)相似。
(2) 矩阵\( \boldsymbol{A}^{\mathrm{T}}\)和矩阵\( \boldsymbol{A} \)相似。
(3) 通过矩阵特征值的迹和乘积构造一个相似矩阵\( \left[\begin{array}{cc} 0 & 2 \\ -4 & 6 \end{array}\right] \)
例子:相似矩阵在微分方程中的应用
对于我们先前讨论的方程组\( \displaystyle\frac{d \mathbf{y}}{d t}=\boldsymbol{A} \mathbf{y} \),做变量替换有\(\mathbf{y}= \boldsymbol{V} \mathbf{z} \),则有\( \boldsymbol{V} \displaystyle\frac{d \mathbf{z}}{d t}=\boldsymbol{A} \boldsymbol{V} \mathbf{z} \)。于是$$\frac{d \mathbf{z}}{d t}=\boldsymbol{V}^{-1} \boldsymbol{A} \boldsymbol{V} \mathbf{z}=\boldsymbol{\Lambda}\mathbf{z}$$注意这里的矩阵\(\boldsymbol{\Lambda} \)是一个对角阵,和矩阵\(\boldsymbol{A} \)是相似的。其实现在问题的关键是如何将矩阵\( \boldsymbol{A}\)对角化,对角化的过程就是解耦的过程。回代得到\(\mathbf{z}(t)=e^{\boldsymbol{A} t} \mathbf{z}(0), \quad \mathbf{y}(t)=\boldsymbol{V} e^{\boldsymbol{A} t} \boldsymbol{V}^{-1} \mathbf{y}(0)=\boldsymbol{V} e^{\boldsymbol{A} t} \mathbf{c} \)。将这个公式展开就是\( \mathbf{y}(t)=c_{1} e^{\lambda_{1} t} \mathbf{x}_{1}+c_{2} e^{\lambda_{2} t} \mathbf{x}_{2}+\cdots+c_{n} e^{\lambda_{n} t} \mathbf{x}_{n}\)。如果矩阵\(\boldsymbol{A} \)不可对角化,则将其变换为上三角阵\( \boldsymbol{B} \),回代仍可以求得解函数??。
若尔当标标准型
【若尔当标标准型】(Jordan normal form)的提出是为了解决前面提到的特征向量缺失的问题。下面我们通过几个问题来分析:
(a) 为什么要提出若尔当标准型的概念?
答:因为有的矩阵无法对角化,这类矩阵的特点就是特征向量缺失。为了让这类不能对角化的矩阵也能“对角化”,提出了若尔当标准型的概念。我们传统意义上能对角化的矩阵其实是若尔当矩阵的一个特例而已。
(b) 什么样的情况会有特征向量缺失的情况?
答:如果所有的特征值都不同,那么所有的特征向量都线性无关,也就是一定可以对角化;但是如果存在重复的特征值,那么才可能出现特征向量缺失的情况。
假设\( \lambda\)是矩阵的二重复特征值,那么\(A-\lambda I\)的零空间的维数一定要是二维的(零空间是由特征向量张成的),或者说\(A-\lambda I\)空间的维数一定要是\( n-2 \),这样即使是重复的特征值对应的特征向量也是不相关的。如果不是这种情况,那么必有特征向量缺失,按照GS在线代中讲的,我们称这种矩阵为“退化矩阵”。
(c) 若尔当标准型矩阵的实用性?
答:更侧重研究意义,实际应用意义不大,了解概念即可。回忆一下若尔当块。
矩阵型指数函数
$$e^{\boldsymbol{A}} e^{\boldsymbol{B}} \neq e^{\boldsymbol{B}} e^{\boldsymbol{A}} \neq e^{\boldsymbol{A}+\boldsymbol{B}}$$对于微分方程\(y^{\prime}=(\cos t) y \)
对称矩阵,实特征值,正交特征向量
对称矩阵:\( \boldsymbol{S}^{T}=\boldsymbol{S} \),特征值一定为实数,特征向量正交;
反对称阵:\(\boldsymbol{A}^{T}=-\boldsymbol{A} \),特征值为纯虚数,特征向量也相互正交。
正交矩阵:\( \boldsymbol{Q}^{T} \boldsymbol{Q}=\boldsymbol{I} \),特征向量也相互正交。
厄米特矩阵:\( \overline{\boldsymbol{S}}^{T}=\boldsymbol{S}\),如\(\left[\begin{array}{cc} 1 & i \\ -i & 2 \end{array}\right] \)
二阶常微分方程组
这里介绍二阶常微分方程组\(\mathbf{y}^{\prime \prime}+\boldsymbol{S} \mathbf{y}=0 \),其中\( \boldsymbol{S} \)为对称矩阵。方程中没有阻尼项,且等号右侧没有外力输入项,因此所求解函数为匹配初值的零解。
例子:振荡方程$$\boldsymbol{M} \mathbf{y}^{\prime \prime}+\boldsymbol{K} \mathbf{y}=0$$其中\( \boldsymbol{M} \)为【质量矩阵】,而\( \boldsymbol{K} \)为【刚性矩阵】。在实际应用中,第一步就是建立方程,即确定这些参数矩阵。
解函数形式\( \mathbf{y}=e^{i \omega t} \mathbf{x} \),代入原方程可以得到\(\boldsymbol{M}(i \omega)^{2} e^{i \omega t} \mathbf{y}+\boldsymbol{K} e^{i \omega t} \mathbf{x}=0 \),整理可得\(\boldsymbol{K} \mathbf{x}=\boldsymbol{M} \omega^{2} \mathbf{x} \),转化成了“两个矩阵的特征值问题”。在matlab中,输入eig(K, M)就可以求解出“两个矩阵的特征值问题”中的特征值\( \omega^{2} \)和特征向量\( \mathbf{x} \)。在大多数实际情况中,质量矩阵是常数乘以单位矩阵\( \boldsymbol{M}=c\boldsymbol{I} \)。
对于二阶常微分方程组\(\mathbf{y}^{\prime \prime}+\boldsymbol{S} \mathbf{y}=0 \),通常给定的初值包含\( \mathbf{y}(0)\)和\( \mathbf{y}^{\prime}(0) \),这两个向量包含\( 2n\)个初值,因此需要\( 2n \)个解函数与之匹配。
例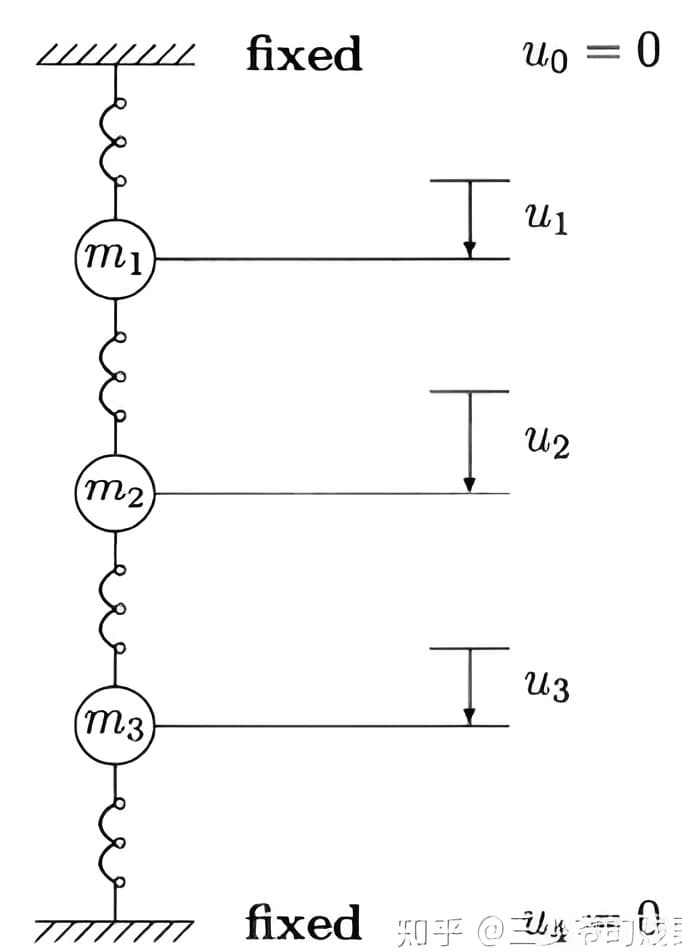 :二阶微分方程组\(\boldsymbol{M} \mathbf{y}^{\prime \prime}+\boldsymbol{K} \mathbf{y}=0 \)描述了三个重物的运动,因此方程数为\( \mathrm{n}=3\)。假定三个重物质量相等,则有\(\boldsymbol{M}=m\boldsymbol{I} \),不存在外力输入作用,也不存在阻尼,方程组的解就是重物的运动轨迹,即位移随时间的变化。系统没有能量输入,也没有能量输出,物体的运动模式为纯简谐运动,但这些振动是相互耦合的。
:二阶微分方程组\(\boldsymbol{M} \mathbf{y}^{\prime \prime}+\boldsymbol{K} \mathbf{y}=0 \)描述了三个重物的运动,因此方程数为\( \mathrm{n}=3\)。假定三个重物质量相等,则有\(\boldsymbol{M}=m\boldsymbol{I} \),不存在外力输入作用,也不存在阻尼,方程组的解就是重物的运动轨迹,即位移随时间的变化。系统没有能量输入,也没有能量输出,物体的运动模式为纯简谐运动,但这些振动是相互耦合的。
刚度矩阵$$\boldsymbol{K}=k\left[\begin{array}{ccc} 2 & -1 & 0 \\ -1 & 2 & -1 \\ 0 & -1 & 2 \end{array}\right]$$令\( \boldsymbol{S}={\boldsymbol{K}}{\boldsymbol{M}}^{-1}=\displaystyle\frac{\boldsymbol{K} \boldsymbol{I}^{-1}}{m}\),则\( \boldsymbol{K} \mathbf{x}=\boldsymbol{M} \omega^{2} \mathbf{x} \)变为\(\boldsymbol{S }\mathbf{x}=\omega^{2} \mathbf{x}=\lambda \mathbf{x} \)。
在有限元方法和弹簧系统中,刚度矩阵\( \boldsymbol{K} \)是【对称半正定矩阵】,其将胡克定律中的刚度推广为矩阵形式,描述了所有自由度之间的刚度,从而得到\( \mathbf{F}=-K \mathbf{x}\),而\(U=\displaystyle\frac{1}{2} \mathbf{x}^{\mathrm{T}} K \mathbf{x} \)是系统的总势能。就我们这里的刚度矩阵来说,第一个重物受到的作用力来自上下两个弹簧,上面弹簧的作用为\( k y_{1}\),下面的弹簧的作用为\( -k\left(y_{2}-y_{1}\right) \),合力为\(k\left(2 y_{1}-y_{2}\right) \),其他以此类推。
解函数为\( \mathbf{y}=A_{1}\left(\cos \omega_{1} t\right) \mathbf{x}_{1}+B_{1}\left(\sin \omega_{1} t\right) \mathbf{x}_{1}+\cdots \)是六个解的线性组合。根据两个初值(位置和速度参数)可以分别确定余弦函数和正弦函数前面的参数。
例:
 $$\mathbf{y}^{\prime \prime}+\frac{k}{m}\left[\begin{array}{cc} 2 & -1 \\ -1 & 2 \end{array}\right] \mathbf{y}=0$$矩阵\( S=\displaystyle\frac{k}{m}\left[\begin{array}{cc} 2 & -1 \\ -1 & 2 \end{array}\right] \)的特征值为\(\lambda_{1}=1 \times \displaystyle\frac{k}{m} \)和\( \lambda_{2}=3 \times \displaystyle\frac{k}{m} \)。假设初始时刻,两个物体的速度都为零\( \mathbf{y}^{\prime}(0)=0 \),即前面的参数\( B \)都是零,则解函数$$\mathbf{y}(t)=A_{1}(\cos \sqrt{\frac{k}{m}} t)\left[\begin{array}{l} 1 \\ 1 \end{array}\right]+A_{2}(\cos \sqrt{\frac{3 k}{m}} t)\left[\begin{array}{c} 1 \\ -1 \end{array}\right]$$其中的采纳数\( A \)取决于物体的初始位置\( \mathbf{y}(0)\)。
$$\mathbf{y}^{\prime \prime}+\frac{k}{m}\left[\begin{array}{cc} 2 & -1 \\ -1 & 2 \end{array}\right] \mathbf{y}=0$$矩阵\( S=\displaystyle\frac{k}{m}\left[\begin{array}{cc} 2 & -1 \\ -1 & 2 \end{array}\right] \)的特征值为\(\lambda_{1}=1 \times \displaystyle\frac{k}{m} \)和\( \lambda_{2}=3 \times \displaystyle\frac{k}{m} \)。假设初始时刻,两个物体的速度都为零\( \mathbf{y}^{\prime}(0)=0 \),即前面的参数\( B \)都是零,则解函数$$\mathbf{y}(t)=A_{1}(\cos \sqrt{\frac{k}{m}} t)\left[\begin{array}{l} 1 \\ 1 \end{array}\right]+A_{2}(\cos \sqrt{\frac{3 k}{m}} t)\left[\begin{array}{c} 1 \\ -1 \end{array}\right]$$其中的采纳数\( A \)取决于物体的初始位置\( \mathbf{y}(0)\)。
从解函数中两个特征向量可以看出,有两种基本的运动模式,其一就是两物体相同振动(第一项),其二是相向运动(第二项),而且第二项的运动频率更高。重物的运动模式就是低频的同向运动和高频的相向运动的组合。如果是三个重物的系统,那么对应矩阵有三个特征向量,得到的振动模式有三种,那么每一个物体的振动模式都是这三者的叠加。
如果系统处在且仅处在这两个模式(这两个解)的任意一个中,系统将以某个特定的频率和某种特定的模式振动下去,并且,系统会很和谐地维持这个运动状态,在任何时候都不会掺杂其他模式的任何一点成分。于是乎,这个系统将变得很好处理,这也就是我们这么设出这个解的理由。在这里,我们叫这个特定的频率为系统的【简正频率】,我们叫这个特定的振动模式为这个系统的【简正模】。坐标\( \mathbf{y}(t)\)为这个系统的【简正坐标】,系统的运动就是两个简正坐标在简正模下的线性组合。这一段来自这里。
正定矩阵(Positive Definite Matrices)
若尔当标标准
前面介绍二阶微分方程组\(\mathbf{y}^{\prime \prime}+\boldsymbol{S} \mathbf{y}=0 \)的应用中,解函数形式\(\mathbf{y}=e^{i \omega t} \mathbf{x} \),其实就是要求\( \boldsymbol{S} \mathbf{x}=\omega^{2} \mathbf{x}=\lambda \mathbf{x} \)中的特征值和特征向量。其中的特征值\( \lambda= \omega^{2}\)为非负的。
正定矩阵:对称矩阵,而且所有特征值都大于零;
半正定矩阵:对称矩阵,而且所有的特征值都不小于零。
对于任意矩阵\(\boldsymbol{A} \),\(\boldsymbol{A}^{\mathrm{T}} \boldsymbol{A} \)一定是方阵,也是对称矩阵,同时也至少的半正定的。
判定一个矩阵是否是正定的,不用计算每一个特征值,只需要判断所有特征值的符号。给出五个等价的判断途径来确定是否为正定:
以二阶矩阵\( \left[\begin{array}{ll} a & b \\ c & d \end{array}\right]\)为例,例如\(S=\left[\begin{array}{ll} 4 & 6 \\ 6 & 10 \end{array}\right] \)
(1) 所有特征值都大于零;
(2) 所有主元大于零:比如例子中的主元分别为4和1,都大于零;
(3) 所有左上行列式大于零;
(4) \( \boldsymbol{S}=\boldsymbol{A}^{\mathrm{T}} \boldsymbol{A}\),矩阵\( \boldsymbol{A}\)列向量线性无关;
(5) 表达式\(\mathbf{x}^{\mathrm{T}} \boldsymbol{S} \mathbf{x}>0 \),其中\( \mathbf{x}\not=0 \)。这是最好的正定的定义,而前面几条都是用来验证正定性的条件。\( \mathbf{x}^{\mathrm{T}} \boldsymbol{S} \mathbf{x}>0 \)有时被用来计算能力,因此整个定义又被称为能量定义。
一元函数极值点:一阶导数为零,二阶导数大于零则为极小值,二阶导数小于零则为极大值;
多元函数极值点:一阶导数为零,二阶偏导数矩阵是正定,那么是极小值点。
例子:在金融学中常问到一个矩阵\(\left[\begin{array}{lll} 1 & a & b \\ a & 1 & c \\ b & c & 1 \end{array}\right] \)是否是正定。这是一个相关系数矩阵,描述了债券、股票和外汇之间的相互关联。对于一个低阶矩阵的正定性判断,推荐行列式判断,此处三个行列式分别是:\(1>0, \quad 1-a^{2}>0, \quad 1+2 a b c-a^{2}-b^{2}-c^{2}>0 \)。前两个肯定满足,所以第三个不等式就是判据。
奇异值分解(SVD)
对于任意矩阵,均可以按照\(\boldsymbol{A}=\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{T} \)的形式分解,其中\( \boldsymbol{U} \)和\(\boldsymbol{V} \)均为正交矩阵,而\(\boldsymbol{\Sigma} \)表示的是对角阵。关于这部分内容,直接去看线性代数的笔记。
例子:\(\boldsymbol{A}=\left[\begin{array}{ll} 2 & 2 \\ 1 & 1 \end{array}\right]=\displaystyle\frac{1}{\sqrt{5}}\left[\begin{array}{cc} 2 & 1 \\ -1 & 2 \end{array}\right]\left[\begin{array}{cc} \sqrt{10} & \\ & 0 \end{array}\right] \frac{1}{\sqrt{2}}\left[\begin{array}{cc} 1 & 1 \\ 1 & -1 \end{array}\right] \)
应用举例:
对三个人的四种基因进行测试,得到基因表达的矩阵,每一个元素代表该列所代表的的人在该行所代表的基因组中的表达情况,这是一个\( 4 \times 3 \)的矩阵。而最重要的信息来自于最大的奇异值,以及与之对应的矩阵\( \boldsymbol{U} \)的列向量和矩阵\( \boldsymbol{V}\)中的行向量,三者的乘积(比如\( \mathbf{u}_{1} \sigma_{1} \mathbf{v}_{1}^{T} \))具有最大的信息量。这就是“主成分分析”(principal component analysis)。其中\( \mathbf{u}_{1} \)代表人的线性组合,而\( \mathbf{v}_{1}\)代表基因的线性组合。关于PCA,可以看看这里。