计算机零散小知识汇总 机器学习,神经网络,卷积,人脸识别
旅行推销员问题
浅说计算
参考资:蔡司工程师-陈维军视频
万物皆可数字化,每一个数学都已经/将被计算。
其中包括A/D,D/A,encoding/decoding,Transfrm,Rescaling,Detection/Recognition,Modeling/Mapping,Morphing/Synthesis,Machine Learning,Visualization/Virtualization等等。
很多人不了解,计算其实是一堆加法,减法可以看作是加上对应的负数,乘法可以看作是一堆数相加,除法 = 减法+加法(循环),幂次运算可以看作是乘法,而乘法本身也是加法,三角函数/其他函数可以用泰勒展开,然后转化为其他运算,最后同样都可以变成加法的形式。
加法就是状态转换和移位(Addition is just state replacing and shift),不仅是针对十进制,其他比如二进制、十六进制也是一样。
 计算可仅被一系列状态转换和移位来完成(Computing could be fulfilled by only/just replacing and shift),这是1936年图灵提出来的。图灵机的本身就是状态转换和移位。图灵机是由冯诺依曼架构来实现的,即计算可以被状态读取/改变架构完全实现(Computing could be implemented as a state visiting/replacing architecture)
计算可仅被一系列状态转换和移位来完成(Computing could be fulfilled by only/just replacing and shift),这是1936年图灵提出来的。图灵机的本身就是状态转换和移位。图灵机是由冯诺依曼架构来实现的,即计算可以被状态读取/改变架构完全实现(Computing could be implemented as a state visiting/replacing architecture)
Turing machine just change the state and shift the tape.
Von Neumann architecture just mixture the instruction and data.
Computer language is generally: instruction + data
Computer program is sequence of instruction +data
二进制计算与越来越密集的“与非门”(Computing in binary by more and more NAND gate)。这里补充一下半加法器和对应三极管电路,还有全加法器。
Fast computing: parallelism-1, multi-stage pipeline 快速计算并行方案-1,流水线。
Fast computing: parallelism-2, SIMD 快速计算并行方案-2,SIMD。
SIMD = Single Instruction, Multiple Data → The key for GPU parallel computing
GPU = Graphics processing unit (GPU可以快速执行矩阵的操作)
Fast computing: parallelism-3, Multiple core + Heterogeneous computing 快速计算并行方案-3,多核/异构。
多核,是从硬件设计的角度来说的,多个CPU,同一个cache/memory;
异构是从软件层面来说的。
The essential nature of computing 计算的本质
沈向阳:computing = indexing +sorting
I understood it as an equivalent physical concept:
Computing = transformation +comparison
Transformation is generally a SIMD type operation.
Comparison is generally a pipeline tasks.
Various transformation (time/spatial) + comparison →Heterogeneous computing
Next step computing-1:
There are several fundamental questions to be answered:
(1) When the computing could/must be performed?
(2) What minimum computing is essentially necessary?
(3) What kinds of physics could be further adopted for computing?
Ultra-high-speed computing via fiber optics.
Next step computing-2:
Two all known but often been ignored facts for both the transformation and the comparison: 0到0其实是不用算的,噪声到噪声也不用算。
Generally, before performing computing on multiple data, we don't know whether they are zero, noise or structural signal.
- Algorithm principle: "Approximate FFT" by Don Coppersmith
- Physical implementation: Quantum computing based on the local coherence (superposition) and natural uncertainty inside a quantum system.
- 计算复杂度从\( N \log N \rightarrow \log N \)。
李永乐—机器学习和神经网络
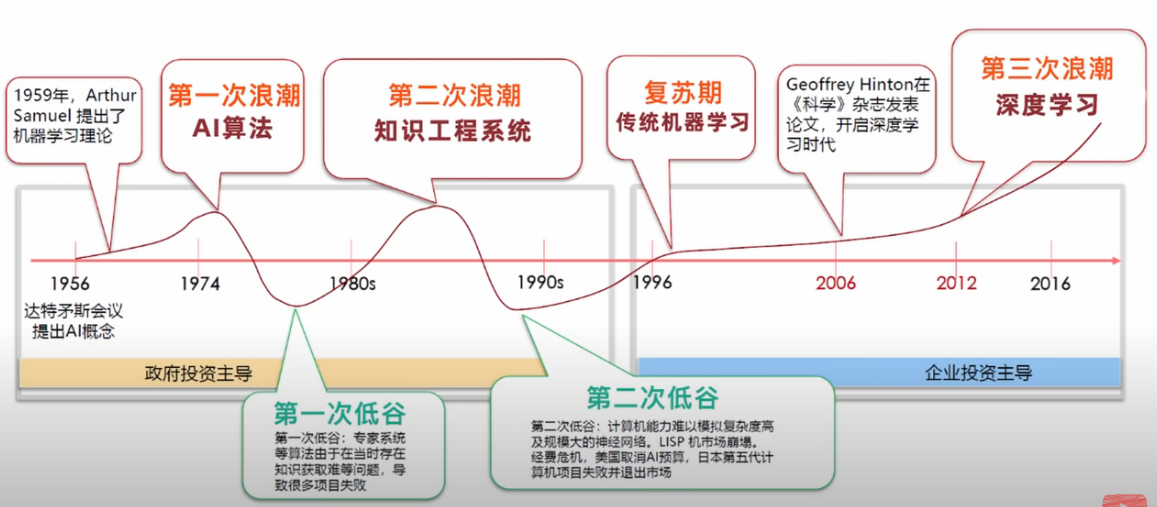 人工智能发展史
人工智能发展史
(1) 1950年,图灵提出的一个关于判断机器是否能够思考的著名思想实验,测试某机器是否能表现出与人等价或无法区分的智能。测试的谈话仅限于使用唯一的文本管道。
(2) 1956年,马文明斯基、约翰麦卡锡、香农召开了达特茅斯会议,主要议题是“机器是否能像人类一样思考”,会议上人们发明了一个词“人工智能(AI)”。
(3) 1997年IBM的机器人“深蓝”,人工智能再次复苏。得益于算法的改进,辛顿将反向传播是算法BP引入到AI,杨立昆的卷积神经网络,等等。
梯度下降算法:预测房价

这里是最简单的例子,房价只和面积有关,于是可以用最小二乘法来拟合房价和面积之间的关系。其中的\( J\)就是损失函数,我们的目标就是找到最小的\( J\)对应的另外两个参数(斜率和截距)。事实上,参数有两个,所以两个参数和损失函数共同构建出的是一个三维图形,上图中为了简便只花了一个。我们的目标其实就是寻找三维图形的两个偏导数同时为零的点;由于计算机处理的数据不是完美连续的,所以上图的停止迭代的条件是取约等于的,具体还要看要求的最终数据精度。
实际上影响房价的因素有很多(每一个输入中包含多个数据),根据不同参数对房价影响的权重不同,我们可以列出:$$y=w_{1} x_{1}+w_{2} x_{2}+\cdots+w_{n} x_{n}+b$$通过一大堆数据,可以找到最优的参数解,这就是“回归”。人工智能另一类重要应用就是“分类”,先让电脑熟悉一大堆猴子的照片,然后下次拿出一张新的猴子或者猫的照片,电脑能够区分是不是猴子。
梯度下降算法训练参数非常类似人的认知过程(皮亚杰认知发展理论),吃一堑长一智。
参考资料:
(1) 最小二乘法 来龙去脉
(2) 高斯和勒让德的争论
(3) 皮亚杰+认知发展理论+李永乐
神经网络
 来源于人类对大脑的认知,树突接收信号之后,经过轴突的处理,有选择地向下一级释放(可以释放,也可以不释放)。美国神经科学家认为,每个神经元都是多输入(从上游多个神经元获得信号),单输出,而且输出要么是0要么是1,这就是M-P模型,下图中的\( f \)即为激活函数,决定向下游输出的信号。比如,典型的激活函数sigmoid函数,这个其实就是MIT-微分方程里面讲的Logistic 方程,这里如果激活函数等于0.5,那么意味着有50%的可能性往下游输出1,同时也有50%的可能性输出0。实际上,人类对事物的判断也是从概率上进行判断(分类)的。将人类的一大堆神经元组合起来,就是上面的“神经网络图”。上面的黑白格子图,就是简答的例子,说明电脑如何识别出这是一个字母X;黑白即为1/0,如果是有灰度,我们同样可以转变成具体灰度数值,如果是彩色RGB同样也可以的,都可以转化成输入的一组数。实际应用中的图像识别或者文章阅读,是需要多层神经元,也就是上图中的“多层神经网络”。
来源于人类对大脑的认知,树突接收信号之后,经过轴突的处理,有选择地向下一级释放(可以释放,也可以不释放)。美国神经科学家认为,每个神经元都是多输入(从上游多个神经元获得信号),单输出,而且输出要么是0要么是1,这就是M-P模型,下图中的\( f \)即为激活函数,决定向下游输出的信号。比如,典型的激活函数sigmoid函数,这个其实就是MIT-微分方程里面讲的Logistic 方程,这里如果激活函数等于0.5,那么意味着有50%的可能性往下游输出1,同时也有50%的可能性输出0。实际上,人类对事物的判断也是从概率上进行判断(分类)的。将人类的一大堆神经元组合起来,就是上面的“神经网络图”。上面的黑白格子图,就是简答的例子,说明电脑如何识别出这是一个字母X;黑白即为1/0,如果是有灰度,我们同样可以转变成具体灰度数值,如果是彩色RGB同样也可以的,都可以转化成输入的一组数。实际应用中的图像识别或者文章阅读,是需要多层神经元,也就是上图中的“多层神经网络”。
BP算法就是说,对于多层神经网络,先调整最后一层的参数,然后调整次最后一层的参数,不断往前倒推,所以这叫作反向传播算法。BP算法以及算力的提升为第三次人工智能发展浪潮提供了基础。
程序员不需要自己去编写算法,利用已写好的算法可以直接实现人工智能。这些写好的算法集成在了人工智能框架中,程序员只需要继续在框架这个工具之上开展工作即可。主流AI框架有谷歌的TensorFlow,亚马逊的SageMaker,微软的CNTK,脸书的PyTorch。在AI时代,拥有框架就像通信行业拥有行业标准一样,会占有全行业基础性的优势。华为的AI框架为MindSpore。
李永乐—卷积神经网络-人脸识别啥原理?
视觉原理
1981年诺贝尔生理学或医学奖,科学家把电极插入到猫的脑中,然后给猫看各种各样的图片,研究猫的脑部反应,结果发现大脑中和视觉相关的细胞分为两种,第一种叫作“简单的视觉神经细胞”,特点是某一些线条是比较敏感的,另一类是比较复杂的细胞,不光能对线条产生反应,还能对线条的运动产生反应。于是科学家以此去解释人的眼镜是如何看到物体的。

在他们的启发下,日本科学家福岛彦邦提出了“神经认知模型”,人的大脑中有很多皮层,是一层一层对视觉信号进行处理的。光线刚进入到人的视网膜,我们看到的光线实际上是一大堆像素点,然后在第一个皮层中,抽象出一些特征,比如边缘和方向信息,下一个皮层将这些特征组合起来,形成这个物体的轮廓以及更多的细节,最后把轮廓和细节组合起来形成一个整体的判断。
杨立昆以此发明出一种能够实用的图像识别的算法,称为卷积神经网络,简写为CNN,图像识别中最流行的算法就是卷积神经网络。
计算机实际上是把一幅图转化为一大堆数字,通过训练就知道数字代表什么含义。如果用上节课的方法去训练费时费力,而且一旦图片发生旋转、缩放,计算机就认不出来。但是人眼的效率很高,看过一次汽车和摩托车之后,就能立刻把它们的区别分辨出来,下次看到这个摩托车,即使方向(或者位置)变化了,也能识别出来。
卷积
通信专业也有卷积,但是CNN这里的卷积在表现形式上不同。比如图像X,有多种写法,但是一定有相同的特征,比如一个斜向右下和一个斜向左下的线。我们希望用一种数学方法(卷积)提取图像中的一些特征。这里我们用的是一个三阶卷积核去和原始的七阶图去乘,然后得到红色的五阶图(特征图)。五阶图中,数字越大的地方,表面其越像卷积核(对应的特征为一个斜向右下的线),即存在一个斜向右下的线。总而言之,通过不同的卷积核,我们就能够对图像进行不同的处理,得到不同的特征图,继而显示出这种特征在原始图像中的分布位置。
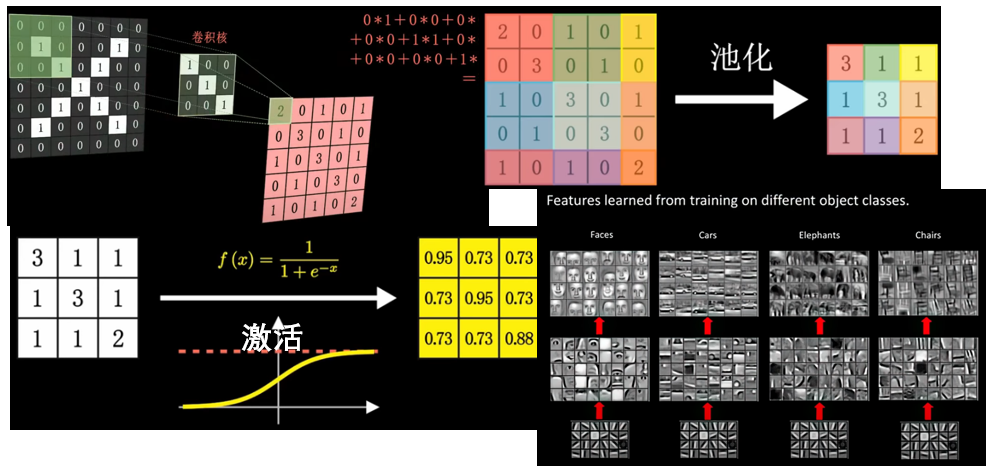
池化、激活
池化过程如图,可以将一个大的特征图变小。激活就是利用之前的sigmoid函数得到一张新的图,激活后的图中元素,数字越接近于1,就越满足卷积核的特性。最开始的卷积核是人为设定的,但是后来在机器学习的过程中,它会根据自己的数据去反向调节这个卷积核,和之前讲的利用训练的方法去调节参数没有什么区别,它最终会找到最合适的卷积核。有几个卷积核,就会有几张特征图,这几张特征图放在一块儿,就形成三维立体的图形。比如这里的图像和三个卷积核作用得到三张图组成的三维图,那么这个三维图池化后可以作为输入,再次进行卷积,不过这个时候的卷积核也是三维的,如果有四个卷积核,那么内积最终得到四张图。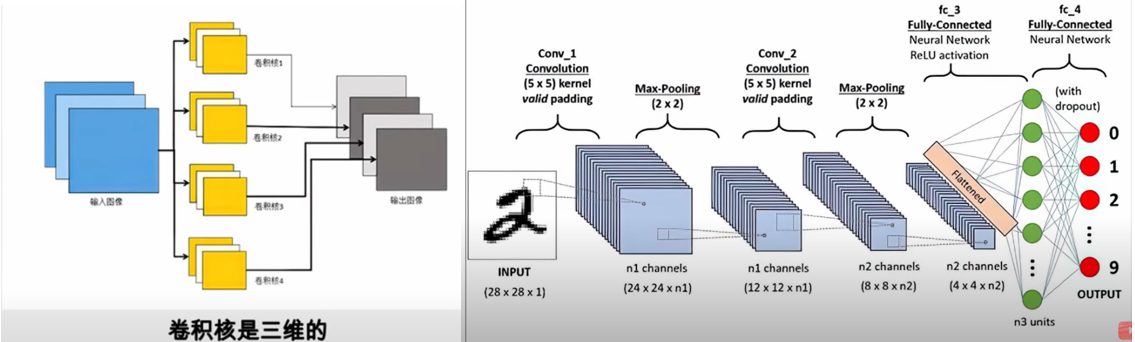
算力
CPU,中央处理器,通用性强,但是并行能力差;
GPU,图形处理器,代表产商是英伟达,之前是用在游戏图像渲染,后来发现可以用于AI,特点是专用型强,并行能力强,类似一万个小学生(只会加减乘除);
NPU,神经网络处理器,专门计算人工智能的处理器,专业性和并行能力都比GPU强,可用于实时美颜。
参考资料:
(1) CPU与GPU到底有什么区别?—脚本之家